
Getting started with Kubernetes
In this multi-part series of articles I'll try and capture everything I think someone who wants to learn and work with Kubernetes should know about. If you have read any of my previous articles or courses you know that I like to learn by practice and trying things out. I'll explain theoretical things, but will focus more on the practical parts.
In this multi-part series of articles about Kubernetes, I'll try and capture what I think everyone who wants to learn and work with Kubernetes should know about.
If you have read any of my previous articles or courses you know that I like to learn and teach by practical examples. As much as I like practical examples, there are a lot of terms and concepts in Kubernetes that you need to understand. But I promise you that once you go through the whole series you will understand the concepts and be able to run an application or a service that uses a database inside Kubernetes.
If you are a beginner to cloud-native, you might want to check out Beginners Guide to Docker to get the basic understanding of Docker. But don't worry, even if you don't know about Docker, you'll be able to follow along.
I will cover the following topics in this first part of the series on learning about Kubernetes:
- What is container orchestration?
- Kubernetes architecture
- Kubernetes resources
- Pods
- ReplicaSets
- Deployments
- Services
After reading this article and going through the examples you will understand what is Kubernetes and learn about Kubernetes building blocks and resources such as Pods, deployments, and services.
From a practical point of view, you will do the following:
- Deploy an application to Kubernetes
- Scale the application
- Access the application using Kubernetes Services
What do I need to start with Kubernetes?
This article is a mix of theory and practice. You'll get the most out of this article if you follow along with the practical examples. To do that you will need the following tools:
- Docker Desktop
- Access to a Kubernetes cluster. See "Which Kubernetes cluster should I use"
- Kubernetes CLI (
kubectl)
Which Kubernetes cluster should I use?
There are multiple options you can go with. The most 'real-world' option would be to get a Kubernetes cluster from one of the cloud providers. However, for multiple reasons that might not be an option for everyone.
The next best option is to run a Kubernetes cluster on your computer. Assuming you have some memory and CPU to spare, you can use one of the following tools to run a single-node Kubernetes cluster on your computer:
To be honest, you could go with any of the above options. Creating Kubernetes replica sets, deployments, and Pods work on any of them. You can also create Kubernetes services, however, things get a bit complicated when you're trying to use a LoadBalancer service type for example.
With the cloud-managed cluster, creating a LoadBalancer service type creates an actual instance of the load balancer and you would get an external/public IP address you can use to access your services.
The one solution from the above list that comes closest to simulating the LoadBalancer service type is Docker Desktop. With Docker Desktop your service gets exposed on an external IP,
localhost. You can access these services using both kind and Minikube as well, however, it requires you to run additional commands.For that purpose, I'll be using Docker Desktop in this article. You can follow the installation instructions for all options from their respective websites.
Kubernetes and contexts
After you've installed one of these tools, make sure you download the Kubernetes CLI. This is a single binary called
kubectl and it allows you to run commands against your cluster. To make sure everything is working correctly, you can run kubectl get nodes to list all nodes in the Kubernetes cluster. You should get an output similar to this one:$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-desktop Ready master 63d v1.16.6-beta.0
You can also check that the context is set correctly to
docker-desktop. Kubernetes uses a configuration file called config to find the information it needs to connect to the cluster. This file is located in your home folder - for example $HOME/.kube/config. Context is an element inside that config file and it contains a reference to the cluster, namespace, and the user. If you're accessing or running a single cluster you will only have one context in the config file. However, you can have multiple contexts defined that point to different clusters.Using the
kubectl config command you can view these contexts and switch between them. You can run the current-context command to view the current context:$ kubectl config current-context
docker-desktop
If you don't get the same output as above, you can use
use-context command to switch to the docker-desktop context:$ kubectl config use-context docker-desktop
Switched to context "docker-desktop".
You can also run
kubectl config get-contexts to get the list of all Kubernetes contexts. The currently selected context will be indicated with * in the CURRENT column:$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
docker-desktop docker-desktop docker-desktop
* minikube minikube minikube
peterjk8s peterjk8s clusterUser_mykubecluster_peterjk8s
There are other commands such as
use-context, set-context, get-contexts, and so on. I prefer to use a tool called kubectx. This tool allows you to quickly switch between different Kubernetes contexts. For example, if I have three clusters (contexts) set in the config file, running kubectx outputs this:$ kubectx
docker-desktop
peterj-cluster
minikube
The currently selected context is also highlighted when you run the command. To switch to the
minikube context, I can run: kubectx minikube.The equivalent commands you can run with
kubectl would be kubectl config get-contexts to view all contexts, and kubectl config use-context minikube to switch the context.Before you continue, make sure your context is set to
docker-desktop if you're using Docker for Mac/Windows.
Let's get started with your journey to Kubernetes and cloud-native with the container orchestration!
What is container orchestration?
Containers are everywhere these days. Tools such as Docker are used to package anything from applications to databases. With the growing popularity of microservice architecture and moving away from the monolithic applications, a monolith application is now a collection of multiple smaller services.
Managing a single application has its own issues and challenges, let alone managing tens of smaller services that have to work together. You need a way to automate and manage your deployments, figure out how to scale individual services, how to use the network and connect them, and so on.
This is where container orchestration steps in. Container orchestration can help you manage the lifecycles of your containers. Using a container orchestration system allows you to do the following:
- Provision and deploy containers based on available resources
- Perform health monitoring on containers
- Load balancing and service discovery
- Allocate resources between different containers
- Scaling the containers up and down
A couple of examples of container orchestrators are Marathon, Docker Swarm and the one I'll be talking about today, Kubernetes.
Kubernetes is an open-source project and one of the popular choices for cluster management and scheduling container-centric workloads. You can use Kubernetes to run your containers, do zero-downtime deployments where you can update your application without impacting your users, and bunch of other cool stuff.

Note
Frequently, you will see Kubernetes being referred to as "K8S". K8S is a numeronym for Kubernetes. The first (K) and the last letter (S) are first and the last letters in the word Kubernetes, and 8 is the number of characters between those two letters. Other popular numeronyms are "i18n" for internationalization or "a11y" for accessibility.
Kubernetes vs. Docker?
I have seen the question about Kubernetes vs. Docker and what the difference is between both. Using Docker you can package your application. This package is called an image or a Docker image. You can think of an image as a template. Using Docker you can create containers from your images. For example, if your Docker image contains a Go binary or a Java application, then the container is a running instance of that application. If you want to learn more about Docker, check out the Beginners Guide to Docker.
Kubernetes on the other hand is a container orchestration tool that knows how to manage Docker (and other) containers. Kubernetes uses a higher-level constructs such as Pods to wrap Docker (or other) containers and gives you the ability to manage them.
Kubernetes vs. Docker Swarm?
Docker Swarm is a container orchestration tool, just like Kubernetes is. You can use it to manage Docker containers. Using Swarm, you can connect multiple Docker hosts into a virtual host. You can then use Docker CLI to talk to multiple hosts at once and run Docker containers on it.
Kubernetes architecture
A Kubernetes cluster is a set of physical or virtual machines and other infrastructure resources that are needed to run your containerized applications. Each machine in a Kubernetes cluster is called a node. There are two types of node in each Kubernetes cluster:
- Master node(s): this node hosts the Kubernetes control plane and manages the cluster
- Worker node(s): runs your containerized applications
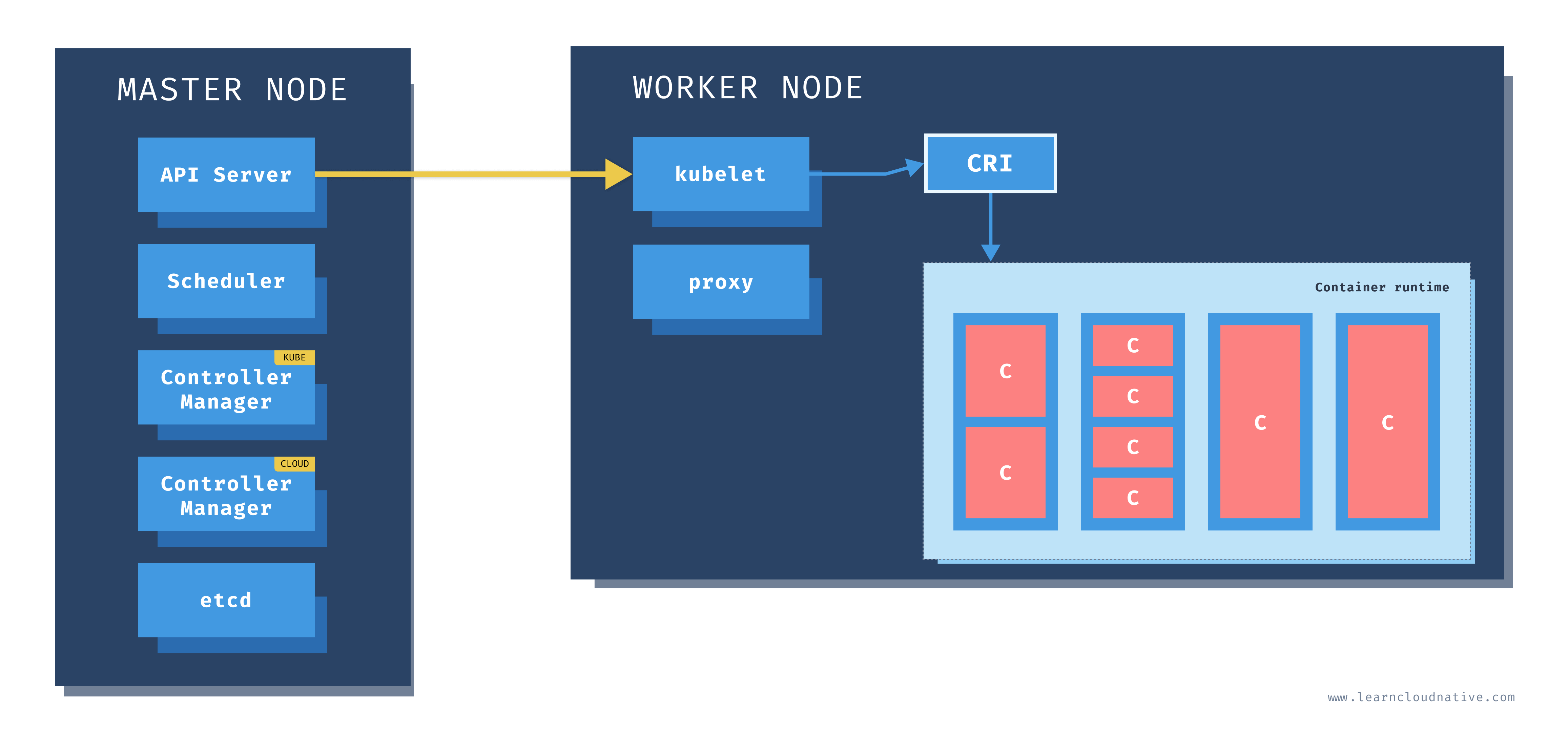
Master node
One of the main components on the master node is called the API server. The API server is the endpoint that Kubernetes CLI (
kubectl) talks to when you're creating Kubernetes resources or managing the cluster.The scheduler component works together with the API server to schedule the applications or workloads on to the worker nodes. It also knows about resources that are available on the nodes as well as the resources requested by the workloads. Using this information it can decide which worker nodes your workloads end up on.
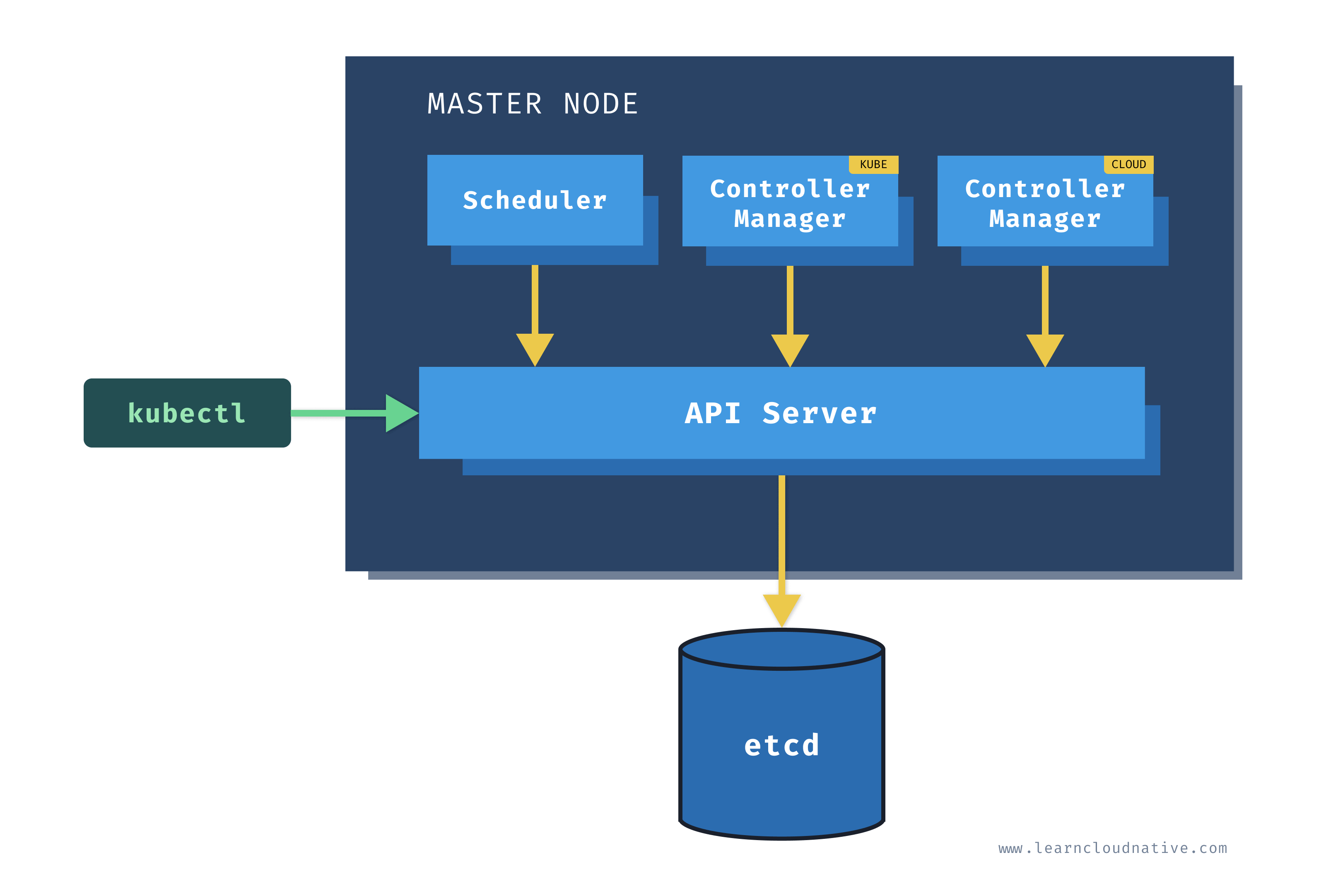
There are two types of controller managers running on master nodes.
The kube controller manager runs multiple controller processes. These controllers watch the state of the cluster and try to reconcile the current state of the cluster (e.g. "5 running replicas of workload A") with the desired state (e.g "I want 10 running replicas of workload A"). The controllers include a node controller, replication controller, endpoints controller, and service account and token controllers.
The cloud controller manager runs controllers that are specific to the cloud provider and can manage resources outside of your cluster. This controller only runs if your Kubernetes cluster is running in the cloud. If you're running Kubernetes cluster on your computer, this controller won't be running. The purpose of this controller is for the cluster to talk to the cloud providers to manage the nodes, load balancers, or routes.
Finally, etcd is a distributed key-value store. The state of the Kubernetes cluster and the API objects is stored in the etcd.
Worker node
Just like on the master node, worker nodes have different components running as well. The first one is the kubelet. This service runs on each worker node and its job is to manage the container. It makes sure containers are running and healthy and it connects back to the control plane. Kubelet talks to the API server and it is responsible for managing resources on the node it's running on.
When a new worker node is added to the cluster, the kubelet introduces itself and provides the resources it has (e.g. "I have X CPU and Y memory"). Then, it asks if any containers need to be run. You can think of the kubelet as a worker node manager.
Kubelet uses the container runtime interface (CRI) to talk to the container runtime. The container runtime is responsible for working with the containers. In addition to Docker, Kubernetes also supports other container runtimes, such as containerd or cri-o.
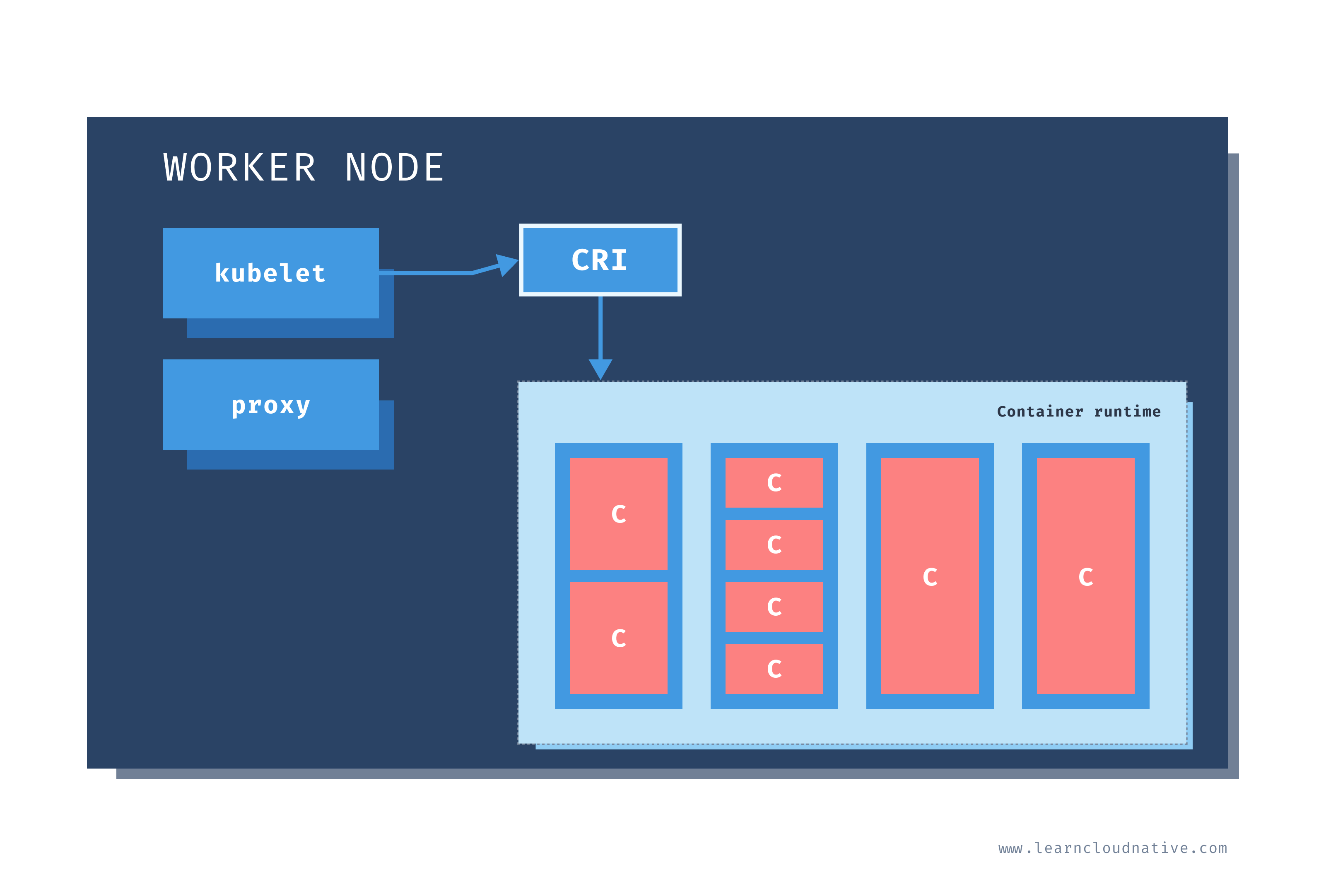
The containers are running inside Pods, represented by the blue rectangles in the above figure (containers are the red rectangles inside each pod). A pod is the smallest deployable unit that can be created, schedule, and managed on a Kubernetes cluster. A pod is a logical collection of containers that make up your application. The containers running inside the same pod also share the network and storage space.
Each worker node also has a proxy that acts as a network proxy and a load balancer for workloads running on the worker nodes. Client requests that are coming through an external load balancer are redirected to containers running inside the pod through these proxies.
Kubernetes resources
The Kubernetes API defines a lot of objects that are called resources, such as namespaces, Pods, services, secrets, config maps, ...
Of course, you can also define your own, custom resources as well using the custom resource definition or CRD.
After you've configured Kubernetes CLI and your cluster, you should try and run
kubectl api-resources command. It will list all defined resources - there will be a lot of them.Resources in Kubernetes can be defined using YAML. YAML (YAML Ain't Markup Language) is commonly used for configuration files and. It is a superset of JSON format, which means that you can also use JSON to describe Kubernetes resources.
Every Kubernetes resource has an
apiVersion and kind fields to describe which version of the Kubernetes API you're using when creating the resource (for example, apps/v1) and what kind of a resource you are creating (for example, Deployment, Pod, Service, etc.).The
metadata includes the data that can help to identify the resource you are creating. This usually includes a name (for example mydeployment) and the namespace where the resource will be created. There are also other fields that you can provide in the metadata, such as labels and annotations, and a couple of them that get added after you created the resource (such as creationTimestamp for example).Pods
Pods are probably one of the most common resources in Kubernetes. They are a collection of one or more containers. The containers within the pod share the same network and storage. This means that any containers within the same pod can talk to each other through
localhost.Pods are designed to be ephemeral, which means that they last for a very short time. Pods can get rescheduled to run on different nodes at any time. This means any time your pod is restarted, your containers will be restarted as well.
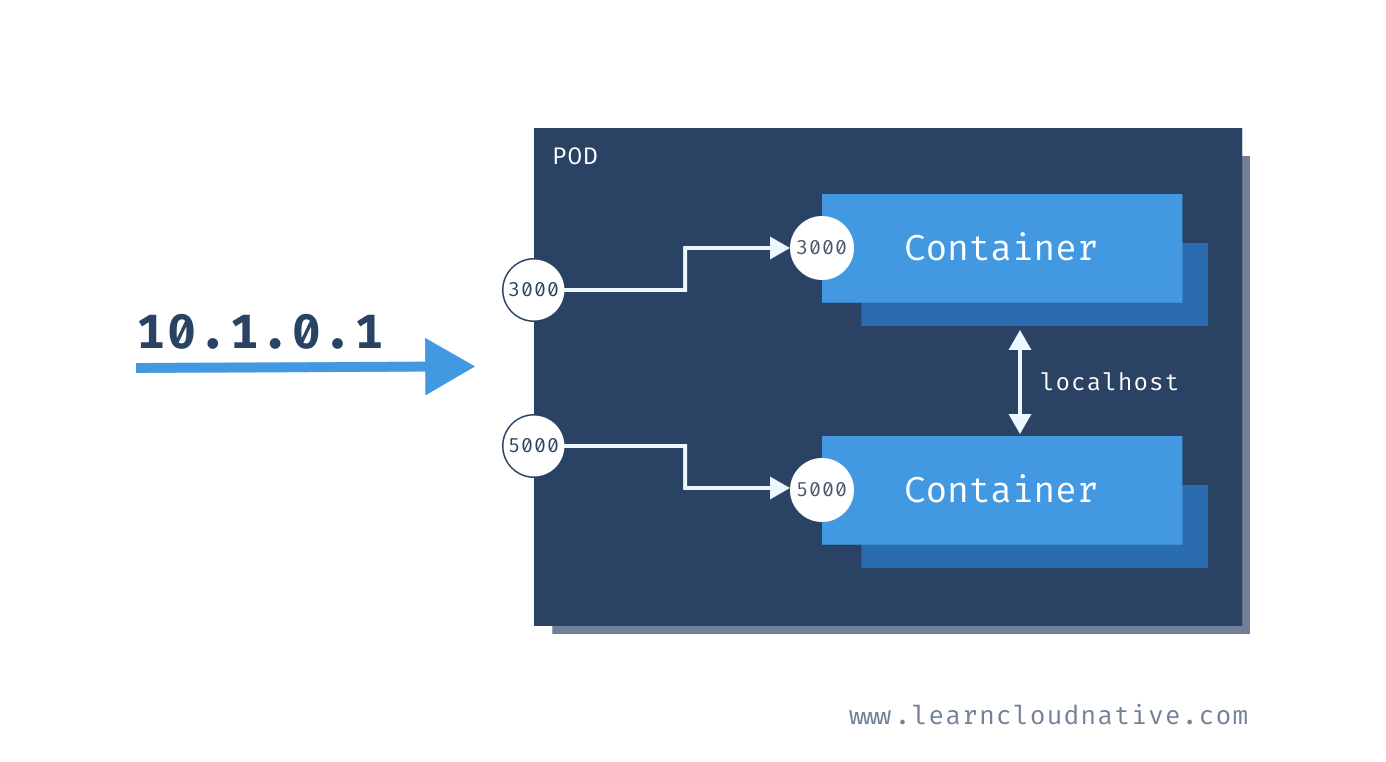
When created, each pod gets assigned a unique IP address. The containers inside your pod can listen to different ports. To access your containers you can use the Pods' IP address. Using the example from the above figure, you could run
curl 10.1.0.1:3000 to communicate to the one container and curl 10.1.0.1:5000 to communicate to the other container. However, if you wanted to talk between containers - for example, calling the top container from the bottom one, you could use http://localhost:3000.If your pod restarts, it will get a different IP address. Therefore, you cannot rely on the IP address. Talking to your Pods directly by the IP is not the right way to go.
An abstraction called a Kubernetes Service is what you can to communicate with your Pods. A Kubernetes Service gives you a stable IP address and DNS name. I'll talk about services later on.
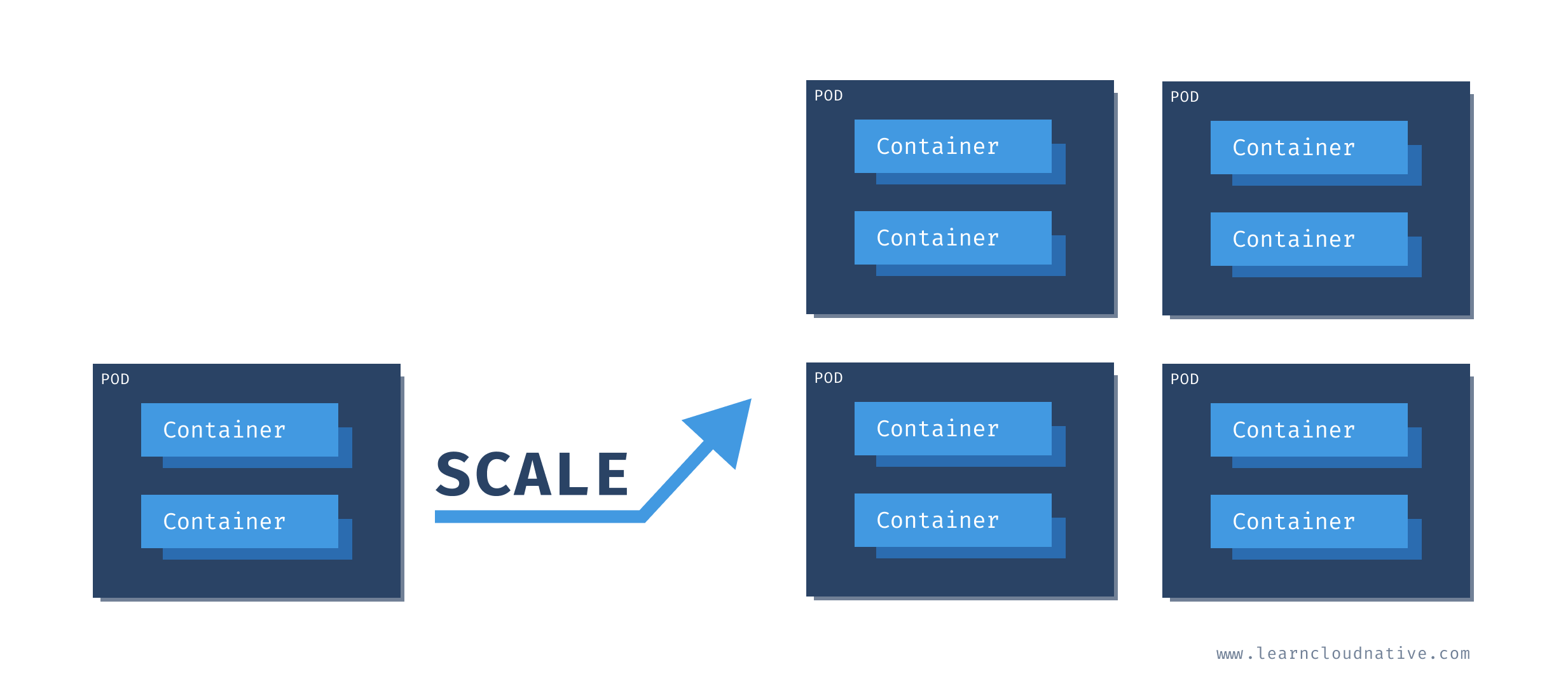
Scaling Pods
All containers within the pod get scaled together. The figure below shows how scaling from a single pod to four Pods would look like. Note that you cannot scale individual containers within the Pods. The pod is the unit of scale.
Note
"Awesome! I can run my application and a database in the same pod!!" No, do not do that!
First, in most cases your database will not scale at the same rate as your application. Remember, you're scaling a pod and all containers inside that pod, not just a single container.
Second, running a stateful workload in Kubernetes, such as a database, is different from running a stateless workload. For example, you need to ensure that data is persistent between pod restarts and that the restarted Pods have the same network identity as the restarted pod. Resources like persistent volumes and stateful sets can be used to achieve this. I will talk more about running stateful workloads in Kubernetes later on.
Creating Pods
Usually, you shouldn't be creating Pods manually. You can do it, but you really should not. The reason being is that if the pod crashes or if it gets deleted, it will be gone forever.
Let's look at how a single pod can be defined using YAML.
apiVersion: v1
kind: Pod
metadata:
name: hello-pod
labels:
app: hello
spec:
containers:
- name: hello-container
image: busybox
command: ['sh', '-c', 'echo Hello from my container! && sleep 3600']
In the first couple of lines, we are defining the kind of resource (
Pod) and the metadata. The metadata includes the name of our pod (hello-pod) and a set of labels that are simple key-value pairs (app=hello).In the
spec section we are describing how the pod should look like. We will have a single container inside this pod, called hello-container, and it will run the image called busybox. When the container has started, the command defined in the command field will be executed.To create the pod, you can save the above YAML into a file called
pod.yaml for example. Then, you can use Kubernetes CLI (kubectl) to create the pod:$ kubectl create -f pod.yaml
pod/hello-pod created
Kubernetes responds with the resource type and the name that it was created. You can use
kubectl get pods to get a list of all Pods running the default namespace of the cluster.$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-pod 1/1 Running 0 7s
You can use the
logs command to see the output from the container running inside the Pod:$ kubectl logs hello-pod
Hello from my container!
Note
In case you'd have multiple containers running inside the same Pod, you could use the-cflag to specify the container name you want to get the logs from. For example:kubectl logs hello-pod -c hello-container
If we delete this Pod using
kubectl delete pod hello-pod, the Pod will be gone forever. There's nothing that would automatically restart the Pod. If you run the kubectl get pods again, you notice the Pod is gone:$ kubectl get pods
No resources found in default namespace.
This is the opposite of the behavior you want. If you have your workload running in a Pod, you would want it to be automatically rescheduled and restarted if something goes wrong.
To make sure the crashed Pods get restarted, you need a controller that can manage the Pods' lifecycle. This controller ensures your Pod is automatically rescheduled if it's deleted or if something bad happens (nodes go down, Pods need to be evicted).
What are ReplicaSets?
The job of a ReplicaSet is to maintain a stable number of Pod copies or replicas. The ReplicaSet controller guarantees that a specified number of identical Pods is running at all times. The replica count is controlled by the
replicas field in the resource definition.If you start with a single Pod and you want to scale to 5 Pods, the ReplicaSet controller uses that current state (one pod) in the cluster and goes and creates four more Pods to meet the desired state (5 Pods). The ReplicaSet also keeps an eye on the Pods, so if you delete one or scale it up or down, it will do the necessary to meet the desired number of replicas. To create the Pods, ReplicaSet uses the Pod template that's part of the resource definition.
But how does ReplicaSet know which Pods to watch and control?
Here's how you can define a ReplicaSet:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: hello
labels:
app: hello
spec:
replicas: 5
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: busybox
command: ['sh', '-c', 'echo Hello from my container! && sleep 3600']
Every Pod that's created by a ReplicaSet can be identified by the
metadata.ownerReferences field. This field specifies which ReplicaSet owns the Pod. If any of the Pods owned by the ReplicaSet is deleted, the ReplicaSet nows about it and acts accordingly (i.e. re-creates the Pod).The ReplicaSet also uses the
selector object and matchLabel to check for any new Pods that it might own. If there's a new Pod that matches the selector labels the ReplicaSet and it doesn't have an owner reference or the owner is not a controller (i.e. if we manually create a Pod), the ReplicaSet will take it over and start controlling it.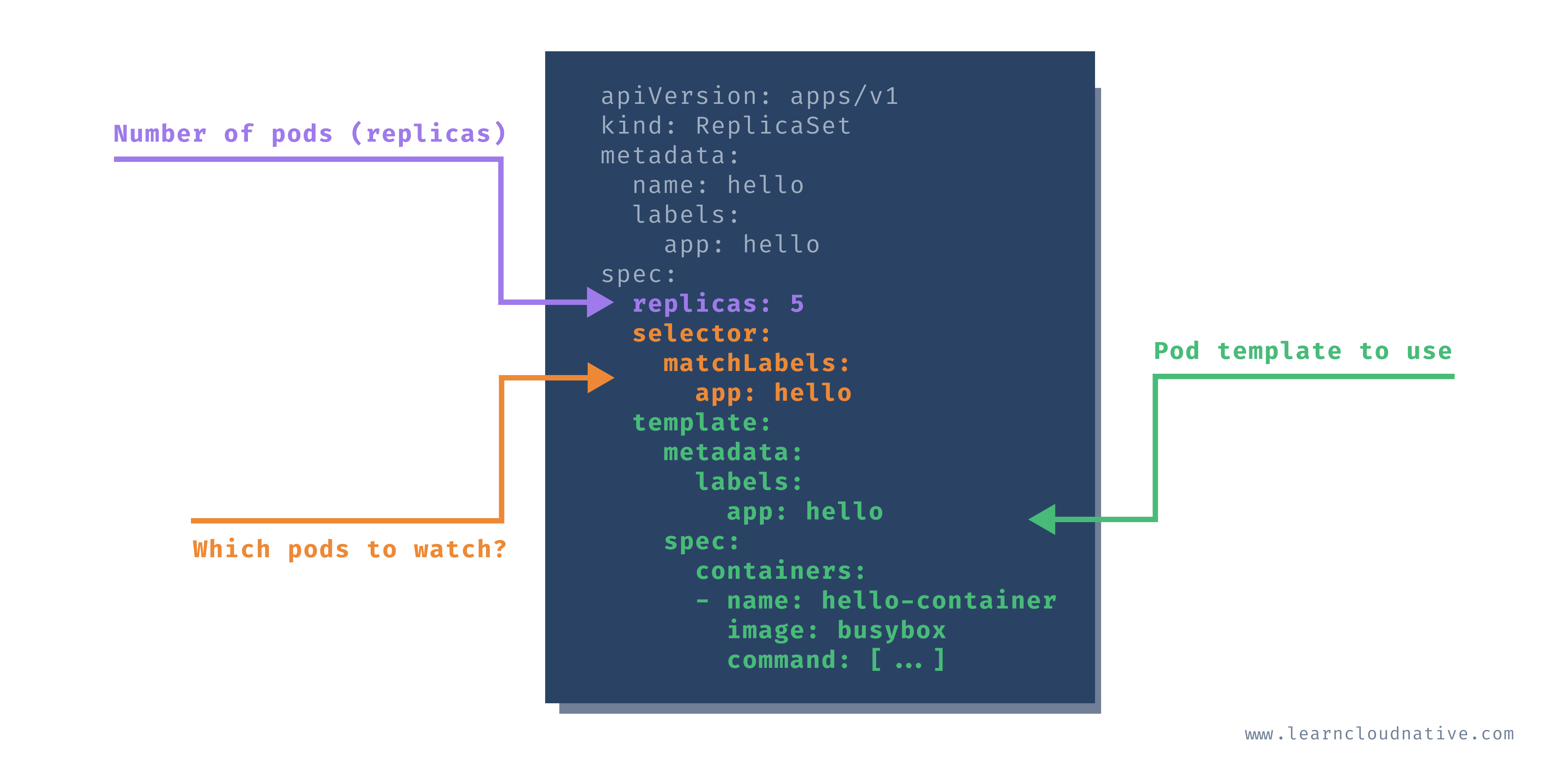
Let's store the above contents in
replicaset.yaml file and run:$ kubectl create -f replicaset.yaml
replicaset.apps/hello created
You can view the ReplicaSet by running the following command:
$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
hello 5 5 5 30s
The command will show you the name of the ReplicaSet and the number of desired, current, and ready Pod replicas. If you list the Pods, you will notice that 5 Pods are running:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-dwx89 1/1 Running 0 31s
hello-fchvr 1/1 Running 0 31s
hello-fl6hd 1/1 Running 0 31s
hello-n667q 1/1 Running 0 31s
hello-rftkf 1/1 Running 0 31s
You can also list the Pods by their labels. For example, if you run
kubectl get po -l=app=hello, you will get all Pods that have app=hello label set. This, at the moment, is the same 5 Pods we created.Let's also look at the owner reference field. We can use the
-o yaml flag to get the YAML representation of any object in Kubernetes. Once we get the YAML, we will search for the ownerReferences string:$ kubectl get po hello-dwx89 -o yaml | grep -A5 ownerReferences
...
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: hello
In the
ownerReferences, the name of the owner is set to hello, and the kind is set to ReplicaSet. This is the ReplicaSet that owns the Pod.Note
Notice how we usedpoin the command to refer to Pods? Some Kubernetes resources have short names that can be used in place of 'full name'. You can usepowhen you meanPodsordeploywhen you meandeployment. To get the full list of supported short names, you can runkubectl api-resources.
Another thing you will notice is how the Pods are named. Previously, where we were creating a single Pod directly, the name of the Pod was
hello-pod, because that's what we specified in the YAML. This time, when using the ReplicaSet, Pods are created using the combination of the ReplicaSet name (hello) and a semi-random string such as dwx89, fchrv and so on.Note
Semi-random? Yes, vowels and numbers 0,1, and 3 were removed to avoid creating 'bad words'.
Let's try and delete one of the Pods. To delete a resource from Kubernetes you use the
delete keyword followed by the resource (e.g. pod) and the resource name hello-dwx89:$ kubectl delete po hello-dwx89
pod "hello-dwx89" deleted
Once you've deleted the Pod, you can run
kubectl get pods again. Did you notice something? There are still 5 Pods running.$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-fchvr 1/1 Running 0 14m
hello-fl6hd 1/1 Running 0 14m
hello-n667q 1/1 Running 0 14m
hello-rftkf 1/1 Running 0 14m
hello-vctkh 1/1 Running 0 48s
If you look at the
AGE column you will notice four Pods that were created 14 minutes ago and one that was created recently. This is the doing of the replica set. When we deleted one Pod, the number of actual replicas decreased from 5 to 4. The replica set controller detected that and created a new Pod to match the desired number of replicas (5).Let's try something different now. We will manually create a Pod that has the labels that match the ReplicaSets selector labels (
app=hello).apiVersion: v1
kind: Pod
metadata:
name: stray-pod
labels:
app: hello
spec:
containers:
- name: stray-pod-container
image: busybox
command: ['sh', '-c', 'echo Hello from stray pod! && sleep 3600']
Store the above YAML in the
stray-pod.yaml file, then create the Pod by running:$ kubectl create -f stray-pod.yaml
pod/stray-pod created
The Pod is created and all looks good. However, if you run
kubectl get pods you will notice that the stray-pod is nowhere to be seen. What happened?The ReplicaSet makes sure only five Pod replicas are running. When we manually created the
stray-pod with the label (app=hello) matching the selector label on the ReplicaSet, the ReplicaSet took that new Pod for its own. Remember, manually created Pod didn't have the owner. With this new Pod under ReplicaSets' management, the number of replicas was six and not five as stated in the ReplicaSet. Therefore, the ReplicaSet did what it's supposed to do, it deleted the new Pod to maintain the five replicas.Zero-downtime updates?
I mentioned zero-downtime deployments and updates earlier. How can that be done using a replica set? Well, it can't be done. At least not in a zero-downtime manner.
Let's say we want to change the Docker image used in the original replica set from
busybox to busybox:1.31.1. We could use kubectl edit rs hello to open the replica set YAML in the editor, then update the image value.Once you save the changes - nothing will happen. Five Pods will still keep running as if nothing has happened. Let's check the image used by one of the Pods:
$ kubectl describe po hello-fchvr | grep image
Normal Pulling 14m kubelet, docker-desktop Pulling image "busybox"
Normal Pulled 13m kubelet, docker-desktop Successfully pulled image "busybox"
Notice it's referencing the
busybox image, but there's no sign of the busybox:1.31.1 anywhere. Let's see what happens if we delete this same Pod:$ kubectl delete po hello-fchvr
pod "hello-fchvr" deleted
From the previous test we did, we already know that ReplicaSet will bring up a new Pod (
hello-q8fnl in our case) to match the desired replica count. If we run describe against the new Pod that came up, you will notice how the image is changed this time:$ kubectl describe po hello-q8fnl | grep image
Normal Pulling 74s kubelet, docker-desktop Pulling image "busybox:1.31"
Normal Pulled 73s kubelet, docker-desktop Successfully pulled image "busybox:1.31"
Similar would happen if we delete the other Pods that are still using the old image (
busybox). The ReplicaSet would start new Pods and this time the Pods would use the new image busybox:1.31.1.There is another resource that can be used to manage the ReplicaSets and allows us to update Pods in a controlled manner. Upon changing the image name it can start Pods using the new image names in a controlled manner. This resource is called a Deployment.
To delete all Pods you need to delete the ReplicaSet by running:
kubectl delete rs hello. rs is the short name for replicaset. If you list the Pods (kubectl get po) right after you issued the delete command you will see the Pods being terminated:NAME READY STATUS RESTARTS AGE
hello-fchvr 1/1 Terminating 0 18m
hello-fl6hd 1/1 Terminating 0 18m
hello-n667q 1/1 Terminating 0 18m
hello-rftkf 1/1 Terminating 0 18m
hello-vctkh 1/1 Terminating 0 7m39s
Once replica set terminates all Pods, they will be gone, and so will be the ReplicaSet.
Deployments
A deployment resource is a wrapper around the ReplicaSet that allows doing controlled updates to your Pods. For example, if you want to update image names for all Pods, you can update the Pod template and the deployment controller will re-create Pods with the new image.
If we continue with the same example as we used before, this is how a Deployment would look like:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
labels:
app: hello
spec:
replicas: 5
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: busybox
command: ['sh', '-c', 'echo Hello from my container! && sleep 3600']
The YAML for Kubernetes Deployment looks almost the same as for a ReplicaSet. There's the replica count, the selector labels, and the Pod templates.
Save the above YAML contents in
deployment.yaml and create the deployment:$ kubectl create -f deployment.yaml --record
deployment.apps/hello created
Note
Why the--recordflag? Using this flag we are telling Kubernetes to store the command we executed in the annotation calledkubernetes.io/change-cause. This is useful to track the changes or commands that were executed when the deployment was updated. You will see this in action later on when we do rollouts.
To list all deployments, we can use the
get command:$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello 5/5 5 5 2m8s
The output is the same as when we were listing the ReplicaSets. When we create the deployment, a ReplicaSet was also created:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
hello-6fcbc8bc84 5 5 5 3m17s
Notice how the ReplicaSet name has the random string at the end. Finally, let's list the Pods:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-27s2s 1/1 Running 0 4m2s
hello-6fcbc8bc84-49852 1/1 Running 0 4m1s
hello-6fcbc8bc84-7tpvs 1/1 Running 0 4m2s
hello-6fcbc8bc84-h7jwd 1/1 Running 0 4m1s
hello-6fcbc8bc84-prvpq 1/1 Running 0 4m2s
When we create a ReplicaSet previously, the Pods were named like this:
hello-fchvr. However, this time, the Pod names are a bit longer - hello-6fcbc8bc84-27s2s. The middle random section in the name 6fcbc8bc84 corresponds to the random section of the ReplicaSet name and the Pod names are created by combining the deployment name, ReplicaSet name and a random string.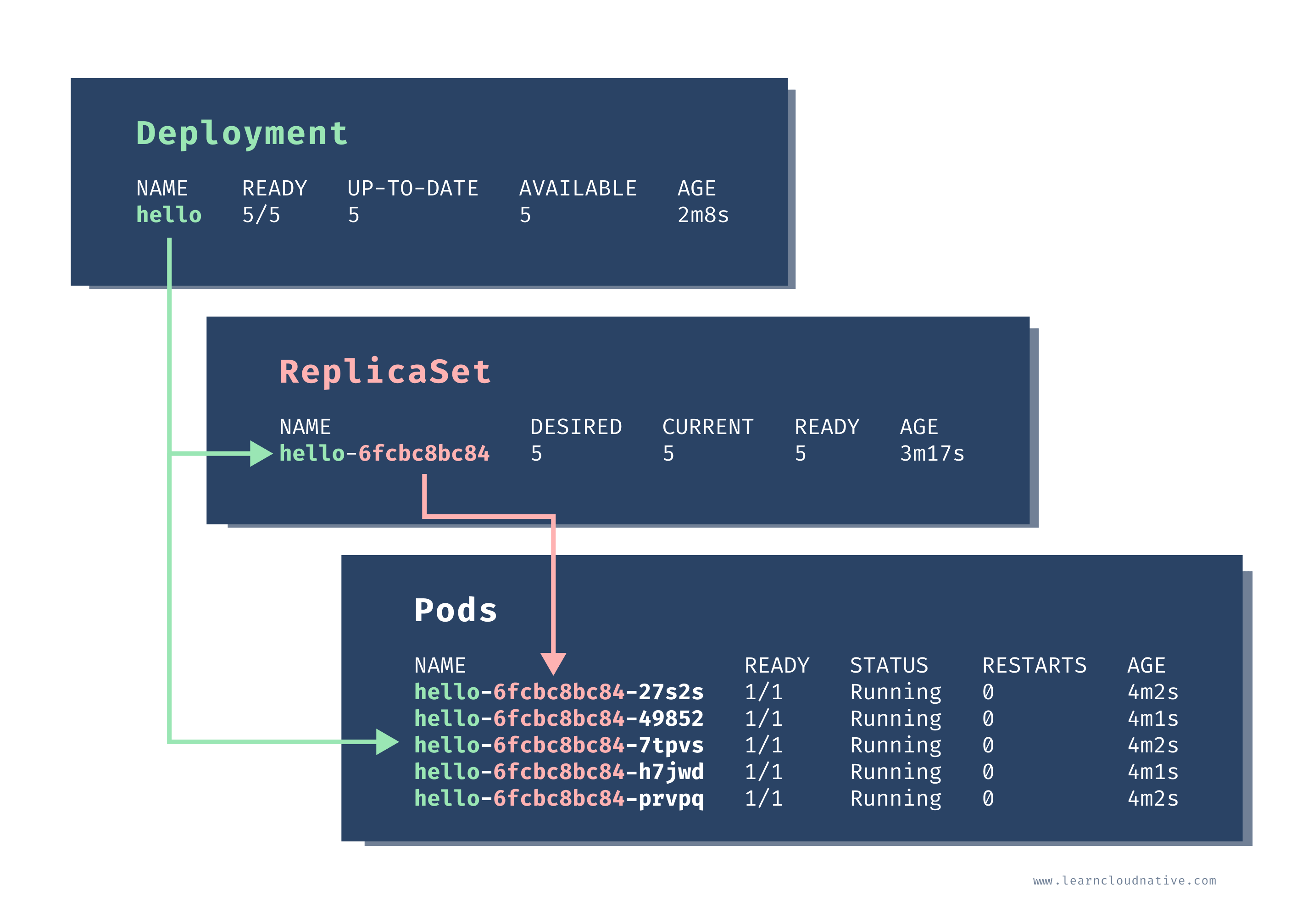
Just like before, if we delete one of the Pods, the Deployment and ReplicaSet will make sure to always maintain the number of desired replicas:
$ kubectl delete po hello-6fcbc8bc84-27s2s
pod "hello-6fcbc8bc84-27s2s" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-49852 1/1 Running 0 46m
hello-6fcbc8bc84-58q7l 1/1 Running 0 15s
hello-6fcbc8bc84-7tpvs 1/1 Running 0 46m
hello-6fcbc8bc84-h7jwd 1/1 Running 0 46m
hello-6fcbc8bc84-prvpq 1/1 Running 0 46m
How to scale the Pods up or down?
There's a handy command in Kubernetes CLI called
scale. Using this command we can scale up (or down) the number of Pods controlled by the Deployment or a ReplicaSet.Let's scale the Pods down to 3 replicas:
$ kubectl scale deployment hello --replicas=3
deployment.apps/hello scaled
$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-49852 1/1 Running 0 48m
hello-6fcbc8bc84-7tpvs 1/1 Running 0 48m
hello-6fcbc8bc84-h7jwd 1/1 Running 0 48m
Similarly, we can increase the number of replicas back to five, and ReplicaSet will create the Pods.
$ kubectl scale deployment hello --replicas=5
deployment.apps/hello scaled
$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-49852 1/1 Running 0 49m
hello-6fcbc8bc84-7tpvs 1/1 Running 0 49m
hello-6fcbc8bc84-h7jwd 1/1 Running 0 49m
hello-6fcbc8bc84-kmmzh 1/1 Running 0 6s
hello-6fcbc8bc84-wfh8c 1/1 Running 0 6s
Updating Pod templates
When we were using a ReplicaSet we noticed that Pods were not automatically restarted when we updated the image name for example. This is something that Deployment can do for us.
Let's use the
set image command to update the image in the Pod templates from busybox to busybox:1.31.1.Note
The commandsetcan be used to update the parts of the Pod template, such as image name, environment variables, resources, and a couple of others.
$ kubectl set image deployment hello hello-container=busybox:1.31.1 --record
deployment.apps/hello image updated
If you run the
kubectl get pods right after you execute the set command, you might see something like this:$ kubectl get po
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-49852 1/1 Terminating 0 57m
hello-6fcbc8bc84-7tpvs 0/1 Terminating 0 57m
hello-6fcbc8bc84-h7jwd 1/1 Terminating 0 57m
hello-6fcbc8bc84-kmmzh 0/1 Terminating 0 7m15s
hello-84f59c54cd-8khwj 1/1 Running 0 36s
hello-84f59c54cd-fzcf2 1/1 Running 0 32s
hello-84f59c54cd-k947l 1/1 Running 0 33s
hello-84f59c54cd-r8cv7 1/1 Running 0 36s
hello-84f59c54cd-xd4hb 1/1 Running 0 35s
Four Pods arebeing terminated (one was already terminated at the time I executed the command) and five new Pods are running. Notice something else in the Pod names? The ReplicaSet sections looks different, right? That's because Deployment scaled down the Pods controlled by the previous ReplicaSet and create a new ReplicaSet that uses the new image we defined.
Remember that
--record flag we set? We can now use rollout history command to view the previous rollouts.$ kubectl rollout history deploy hello
deployment.apps/hello
REVISION CHANGE-CAUSE
1 kubectl create --filename=deployment.yaml --record=true
2 kubectl set image deployment hello hello-container=busybox:1.31.1 --record=true
The history will show us all revisions that were made to the deployment. The first revision is when we initially created the resource and the second one is when we updated the image.
Let's say we rolled out this new image version, but for some reason we want to go back to the previous state. Using the
rollout command we can also roll back to a previous revision of the resource.This can be done using
rollout undo command, like this:$ kubectl rollout undo deploy hello
deployment.apps/hello rolled back
With the undo command we rolled back the changes to the previous revision, which is the original state we were in before we updated the image:
$ kubectl rollout history deploy hello
deployment.apps/hello
REVISION CHANGE-CAUSE
2 kubectl set image deployment hello hello-container=busybox:1.31.1 --record=true
3 kubectl create --filename=deployment.yaml --record=true
Let's remove the deployment by running:
$ kubectl delete deploy hello
deployment.apps "hello" deleted
Deployment strategies
You might have wondered what logic or strategy was used to bring up new Pods or terminate the old ones when we scaled the deployments up and down, and when we updated the image names.
There are two different strategies used by deployments to replace old Pods with new ones. The Recreate strategy and the RollingUpdate strategy. The latter is the default strategy.
Here's a way to explain the differences between the two strategies. Imagine you work at a bank and your job is to manage the tellers and ensure there's always someone working that can handle customer requests. Since this is an imaginary bank, let's say you have a total of 10 desks available and at the moment five tellers are working.

Time for a shift change! The current tellers have to leave their desks and let the new shift come in to take over.
One way you can do that is to tell the current tellers to stop working. They will put up the "Closed" sign in their booth pack up their stuff, get off their seats, and leave. Only once all of them have left their seats, the new tellers can come in, sit down, unpack their stuff, and start working.

Using this strategy there will be downtime where you won't be able to serve any customers. As shown in the figure above you might have one teller working and once he packs up, it will take for the new tellers to sit down and start their work. This is how the Recreate strategy works.
The Recreate strategy terminates all existing (old) Pods (shift change happens) and only when they are all terminated (they leave their booths), it starts creating the new ones (new shift comes in).
Using a different strategy, you can keep serving all of your customers while the shift is changing. Instead of waiting for all tellers to stop working first, you can utilize the empty booths and put your new shift to work right away. That means you might have more than 5 booths working at the same time during the shift change.

As soon as you have 7 tellers working for example (5 from the old shift, 2 from the new shift), more tellers from the old shift can start packing up and new tellers can start replacing them. You could also say that you always want at least 3 tellers working during the shift change and you can also accommodate more than 5 tellers working at the same time.

This is how the RollingUpdate strategy works, where the
maxUnavailable and maxSurge settings specify the maximum number of Pods that can be unavailable and maximum number of old and new Pods that can be running at the same time.Recreate strategy
Let's create a deployment that uses the recreate strategy - notice the highlighted lines show where we specified the strategy.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
labels:
app: hello
spec:
replicas: 5
strategy:
type: Recreate
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: busybox
command: ['sh', '-c', 'echo Hello from my container! && sleep 3600']
Copy the above YAML to
deployment-recreate.yaml file and create it:kubectl create -f deployment-recreate.yaml
To see the recreate strategy in action we will need a way to watch the changes that are happening to the Pods as we update the image version for example.
You can open a second terminal window and use the
--watch flag when listing all Pods - the --watch flag will keep the command running and any changes to the Pods will be outputted to the screen.kubectl get pods --watch
From the first terminal window, let's update the Docker image from
busybox to busybox:1.31.1 by running:kubectl set image deployment hello hello-container=busybox:1.31.1
The output from the second terminal window where we are watching the Pods should look like the one below. Note that I have added the line breaks between the groups.
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-jpm64 1/1 Running 0 54m
hello-6fcbc8bc84-wsw6s 1/1 Running 0 54m
hello-6fcbc8bc84-wwpk2 1/1 Running 0 54m
hello-6fcbc8bc84-z2dqv 1/1 Running 0 54m
hello-6fcbc8bc84-zpc5q 1/1 Running 0 54m
hello-6fcbc8bc84-z2dqv 1/1 Terminating 0 56m
hello-6fcbc8bc84-wwpk2 1/1 Terminating 0 56m
hello-6fcbc8bc84-wsw6s 1/1 Terminating 0 56m
hello-6fcbc8bc84-jpm64 1/1 Terminating 0 56m
hello-6fcbc8bc84-zpc5q 1/1 Terminating 0 56m
hello-6fcbc8bc84-wsw6s 0/1 Terminating 0 56m
hello-6fcbc8bc84-z2dqv 0/1 Terminating 0 56m
hello-6fcbc8bc84-zpc5q 0/1 Terminating 0 56m
hello-6fcbc8bc84-jpm64 0/1 Terminating 0 56m
hello-6fcbc8bc84-wwpk2 0/1 Terminating 0 56m
hello-6fcbc8bc84-z2dqv 0/1 Terminating 0 56m
hello-84f59c54cd-77hpt 0/1 Pending 0 0s
hello-84f59c54cd-77hpt 0/1 Pending 0 0s
hello-84f59c54cd-9st7n 0/1 Pending 0 0s
hello-84f59c54cd-lxqrn 0/1 Pending 0 0s
hello-84f59c54cd-9st7n 0/1 Pending 0 0s
hello-84f59c54cd-lxqrn 0/1 Pending 0 0s
hello-84f59c54cd-z9s5s 0/1 Pending 0 0s
hello-84f59c54cd-8f2pt 0/1 Pending 0 0s
hello-84f59c54cd-77hpt 0/1 ContainerCreating 0 0s
hello-84f59c54cd-z9s5s 0/1 Pending 0 0s
hello-84f59c54cd-8f2pt 0/1 Pending 0 0s
hello-84f59c54cd-9st7n 0/1 ContainerCreating 0 1s
hello-84f59c54cd-lxqrn 0/1 ContainerCreating 0 1s
hello-84f59c54cd-z9s5s 0/1 ContainerCreating 0 1s
hello-84f59c54cd-8f2pt 0/1 ContainerCreating 0 1s
hello-84f59c54cd-77hpt 1/1 Running 0 3s
hello-84f59c54cd-lxqrn 1/1 Running 0 4s
hello-84f59c54cd-9st7n 1/1 Running 0 5s
hello-84f59c54cd-8f2pt 1/1 Running 0 6s
hello-84f59c54cd-z9s5s 1/1 Running 0 7s
The first couple of lines show all five Pods running. Right at the first empty line above (I added that for clarity) we ran the set image command. That caused all Pods to be terminated first. Once they were terminated (second empty line in the output above), the new Pods were being created.
The clear downside of this strategy is that once old Pods are terminated and new ones are starting up, there are no running Pods to handle any traffic, which means that there will be downtime. Make sure you delete the deployment
kubectl delete deploy hello before continuing. You can also press CTRL+C to stop running the --watch command from the second terminal window (keep the window open as we will use it again shortly).Rolling update strategy
The second strategy called RollingUpdate does the rollout in a more controlled way. There are two settings you can tweak to control the process:
maxUnavailable and maxSurge. Both of these settings are optional and have the default values set - 25% for both settings.The
maxUnavailable setting specifies the maximum number of Pods that can be unavailable during the rollout process. You can set it to an actual number or a percentage of desired Pods.Let's say
maxUnavailable is set to 40%. When the update starts, the old ReplicaSet is scaled down to 60%. As soon as new Pods are started and ready, the old ReplicaSet is scaled down again and the new ReplicaSet is scaled up. This happens in such a way that the total number of available Pods (old and new, since we are scaling up and down) is always at least 60%.The
maxSurge setting specifies the maximum number of Pods that can be created over the desired number of Pods. If we use the same percentage as before (40%), the new ReplicaSet is scaled up right away when the rollout starts. The new ReplicaSet will be scaled up in such a way that it does not exceed 140% of desired Pods. As old Pods get killed, the new ReplicaSet scales up again, making sure it never goes over the 140% of desired Pods.Let's create the deployment again, but this time we will use the
RollingUpdate strategy.apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
labels:
app: hello
spec:
replicas: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 40%
maxSurge: 40%
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- name: hello-container
image: busybox
command: ['sh', '-c', 'echo Hello from my container! && sleep 3600']
Save the contents to
deployment-rolling.yaml and create the deployment:$ kubectl create -f deployment-rolling.yaml
deployment.apps/hello created
Let's do the same we did before, run the
kubectl get po --watch from the second terminal window to start watching the Pods.kubectl set image deployment hello hello-container=busybox:1.31.1
This time, you will notice that the new ReplicaSet is scaled up right away and the old ReplicaSet is scaled down at the same time:
$ kubectl get po --watch
NAME READY STATUS RESTARTS AGE
hello-6fcbc8bc84-4xnt7 1/1 Running 0 37s
hello-6fcbc8bc84-bpsxj 1/1 Running 0 37s
hello-6fcbc8bc84-dx4cg 1/1 Running 0 37s
hello-6fcbc8bc84-fx7ll 1/1 Running 0 37s
hello-6fcbc8bc84-fxsp5 1/1 Running 0 37s
hello-6fcbc8bc84-jhb29 1/1 Running 0 37s
hello-6fcbc8bc84-k8dh9 1/1 Running 0 37s
hello-6fcbc8bc84-qlt2q 1/1 Running 0 37s
hello-6fcbc8bc84-wx4v7 1/1 Running 0 37s
hello-6fcbc8bc84-xkr4x 1/1 Running 0 37s
hello-84f59c54cd-ztfg4 0/1 Pending 0 0s
hello-84f59c54cd-ztfg4 0/1 Pending 0 0s
hello-84f59c54cd-mtwcc 0/1 Pending 0 0s
hello-84f59c54cd-x7rww 0/1 Pending 0 0s
hello-6fcbc8bc84-dx4cg 1/1 Terminating 0 46s
hello-6fcbc8bc84-fx7ll 1/1 Terminating 0 46s
hello-6fcbc8bc84-bpsxj 1/1 Terminating 0 46s
hello-6fcbc8bc84-jhb29 1/1 Terminating 0 46s
...
Using the rolling strategy you can keep a percentage of Pods running at all times while you're doing updates. This means that there will be no downtime for your users.
Make sure you delete the deployment before continuing:
kubectl delete deploy hello
Services
Pods are supposed to be ephemeral or short-lived. Once they crash, they are gone and the ReplicaSet ensures to bring up a new pod to maintain the desired number of replicas.
Let's say we are running a web frontend in a container within Pods. Each pod gets a unique IP address, however, due to their ephemeral nature, we cannot rely on that IP address.
Let's create a deployment that runs a web frontend:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
replicas: 1
selector:
matchLabels:
app: web-frontend
template:
metadata:
labels:
app: web-frontend
spec:
containers:
- name: web-frontend-container
image: learncloudnative/helloworld:0.1.0
ports:
- containerPort: 3000
Comparing this deployment to the previous one, you will notice we changed the resource names and the image we are using.
One new thing we added to the deployment is the
ports section. Using the containerPort field we can set the port number that our website server is listening on. The learncloudnative/helloworld:0.1.0 is a simple Node.js Express application.Save the above YAML in
web-frontend.yaml and create the deployment:$ kubectl create -f web-frontend.yaml
deployment.apps/web-frontend created
Run
kubectl get pods to ensure Pod is up and running and then get the logs from the container:$ kubectl get po
NAME READY STATUS RESTARTS AGE
web-frontend-68f784d855-rdt97 1/1 Running 0 65s
$ kubectl logs web-frontend-68f784d855-rdt97
> helloworld@1.0.0 start /app
> node server.js
Listening on port 3000
From the logs, you will notice that the container is listening on port
3000. If we set the output flag to gives up the wide output (-o wide), you'll notice the Pods' IP address - 10.244.0.170:$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-frontend-68f784d855-rdt97 1/1 Running 0 65s 10.244.0.170 docker-desktop <none> <none>
If we delete this pod, a new one will take its' place and it will get a brand new IP address as well:
$ kubectl delete po web-frontend-68f784d855-rdt97
pod "web-frontend-68f784d855-rdt97" deleted
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-frontend-68f784d855-8c76m 1/1 Running 0 7s 10.244.0.171 docker-desktop <none> <none>
Similarly if we scale up the deployment to 4 Pods, we will four different IP addresses:
$ kubectl scale deploy web-frontend --replicas=4
deployment.apps/web-frontend scaled
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-frontend-68f784d855-8c76m 1/1 Running 0 5m23s 10.244.0.171 docker-desktop <none> <none>
web-frontend-68f784d855-jrqq4 1/1 Running 0 18s 10.244.0.172 docker-desktop <none> <none>
web-frontend-68f784d855-mftl6 1/1 Running 0 18s 10.244.0.173 docker-desktop <none> <none>
web-frontend-68f784d855-stfqj 1/1 Running 0 18s 10.244.0.174 docker-desktop <none> <none>
How to access the Pods without a service?
If you try to send a request to one of those IP addresses, it's not going to work:
$ curl -v 10.244.0.173:3000
* Trying 10.244.0.173...
* TCP_NODELAY set
* Connection failed
* connect to 10.244.0.173 port 3000 failed: Network is unreachable
* Failed to connect to 10.244.0.173 port 3000: Network is unreachable
* Closing connection 0
curl: (7) Failed to connect to 10.244.0.173 port 3000: Network is unreachable
The Pods are running within the cluster and that IP address is only accessible from within the cluster.
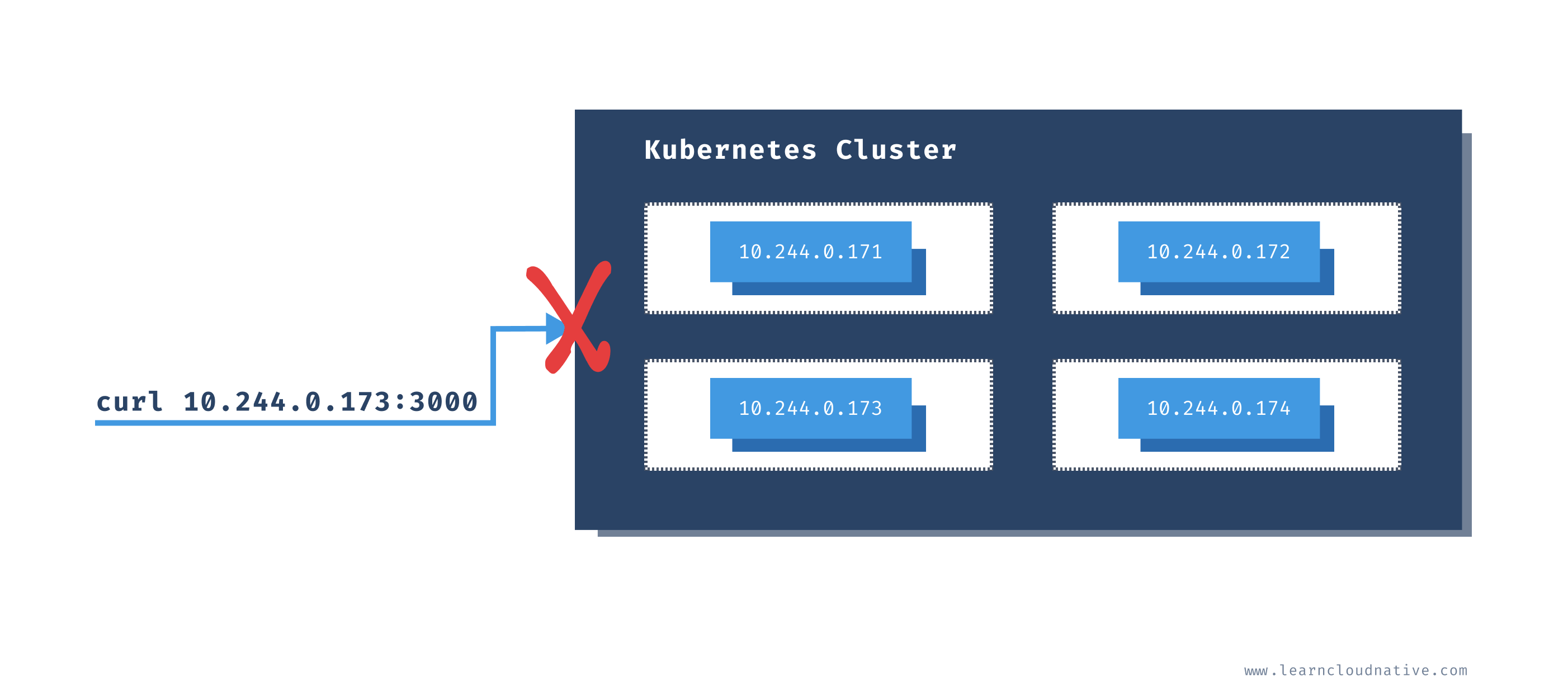
One thing we can do for the testing purposes is to run a Pod inside of the cluster and then get shell access to that pod. Yes, that is possible!
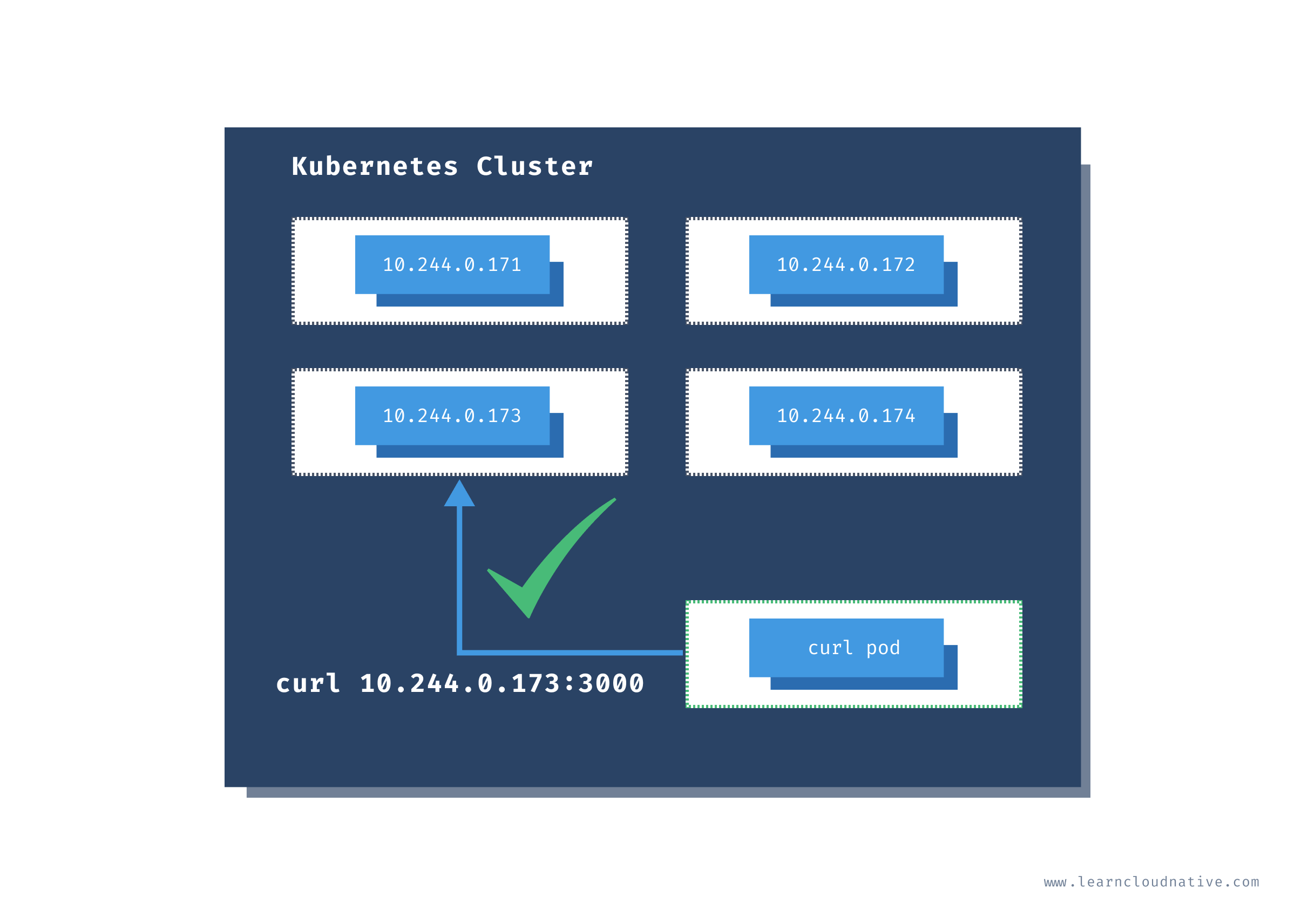
The
radialbusyboxplus:curl is the image I frequently run inside the cluster in case I need to check something or debug things. Using the -i and --tty flags we are want to allocate a terminal (tty) and that we want an interactive session, so we can run commands directly inside the container.I usually name this Pod
curl, but you can name it whatever you like:$ kubectl run curl --image=radial/busyboxplus:curl -i --tty
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$
Now that we have access to the the terminal running inside the container that' inside the cluster, we can run the same cURL command as before:
[ root@curl:/ ]$ curl -v 10.244.0.173:3000
> GET / HTTP/1.1
> User-Agent: curl/7.35.0
> Host: 10.244.0.173:3000
> Accept: */*
>
< HTTP/1.1 200 OK
< X-Powered-By: Express
< Content-Type: text/html; charset=utf-8
< Content-Length: 111
< ETag: W/"6f-U4ut6Q03D1uC/sbzBDyZfMqFSh0"
< Date: Wed, 20 May 2020 22:10:49 GMT
< Connection: keep-alive
<
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
</div>[ root@curl:/ ]$
This time, we get a response from the pod! Make sure you run
exit to return to your terminal. The curl Pod will continue to run and to access it again, you can use the attach command:kubectl attach curl -c curl -i -t
Note
Note that you can get a terminal session to any container running inside the cluster using the attach command.
Accessing Pods using a service
The Kubernetes Service is an abstraction that gives us a way to reliably reach the Pods by their IPs.
The service controller (similar to the ReplicaSet controller) maintains a list of endpoints or the Pod IP addresses. The controller uses a selector and labels to watch the Pods. Whenever a Pod that matches the selector is created or deleted, the controller adds or removes the Pods' IP address from the list of endpoints.
Let's look at how would the Service look like for our website:
kind: Service
apiVersion: v1
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
selector:
app: web-frontend
ports:
- port: 80
name: http
targetPort: 3000
The top part of the YAML should already look familiar - except for the
kind field, it's the same as we saw with the Pods, ReplicaSets, Deployments.The highlighted
selector section is where we define the labels that Service uses to query the Pods. If you go back to the Deployment YAML you will notice that the Pods have this exact label set as well.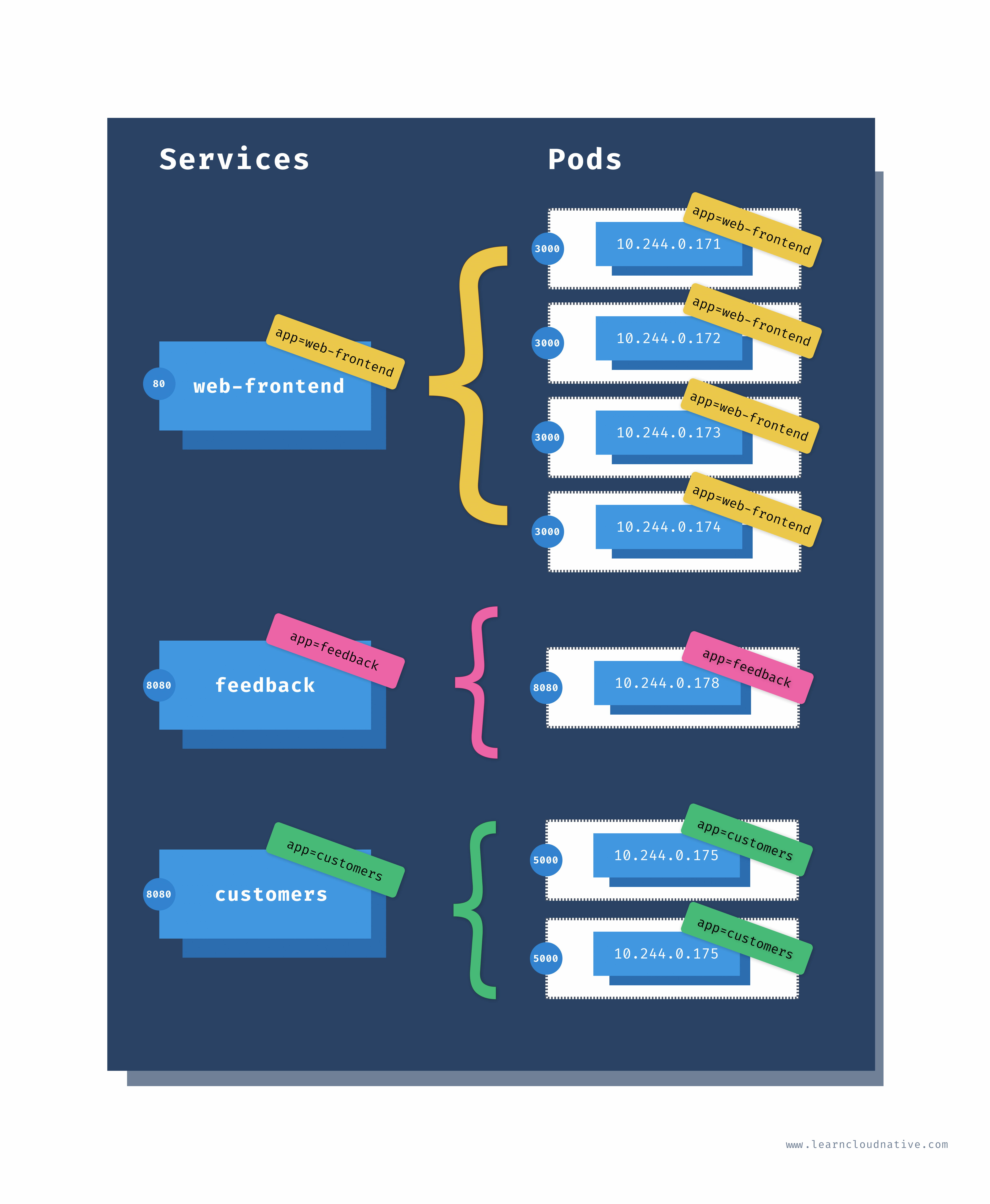
Lastly, under the
ports field we are defining the port where the service will be accessible on (80) and with the targetPort we are telling the service on which port it can access the Pods. The targetPort value matches the containerPort value in the Deployment YAML.Save the service YAML from above to
web-frontend-service.yaml file and deploy it:$ kubectl create -f web-frontend-service.yaml
service/web-frontend created
To see the created service you can run the
get service command:$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d
web-frontend ClusterIP 10.100.221.29 <none> 80/TCP 24s
The
web-frontend service has an IP address that will not change (assuming you don't delete the service) and can be used to reliably access the underlying Pods.Let's attach to the
curl container we started before and try to access the Pods through the service:$ kubectl attach curl -c curl -i -t
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$
Since we set the service port to
80, we can curl directly to the service IP and we will get back the same response as previously:[ root@curl:/ ]$ curl 10.100.221.29
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
</div>
Even though the service IP address is stable and it won't change, it would be much better if we could use a friendlier name to access the service. Every Service you create in Kubernetes gets a DNS name assigned following this format
service-name.namespace.svc.cluster-domain.sample.So far, we deployed everything to the
default namespace and the cluster domain is cluster.local we can access the service using web-frontend.default.svc.cluster.local:[ root@curl:/ ]$ curl web-frontend.default.svc.cluster.local
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
</div>
In addition to using the full name, you can also use just the service name, or service name and the namespace name:
</div>[ root@curl:/ ]$ curl web-frontend
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
[ root@curl:/ ]$ curl web-frontend.default
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
</div>
It is suggested you always use the service name and the namespace name when making requests.
Using the Kubernetes proxy
Another way for accessing services that are only available inside of the cluster is through the proxy. The
kubectl proxy command creates a gateway between your local computer (localhost) and the Kubernetes API server.This allows you to access the Kubernetes API as well as access the Kubernetes services. Note that you should NEVER use this proxy to expose your service to the public. This should only be used for debugging or troubleshooting.
Let's open a separate terminal window and run the following command to start the proxy server that will proxy requests from
localhost:8080 to the Kubernetes API inside the cluster:kubectl proxy --port=8080
If you open
http://localhost:8080/ in your browser, you will see the list of all APIs from the Kubernetes API proxy:{
"paths": [
"/api",
"/api/v1",
"/apis",
"/apis/",
"/apis/admissionregistration.k8s.io",
"/apis/admissionregistration.k8s.io/v1",
"/apis/admissionregistration.k8s.io/v1beta1",
...
For example, if you want to see all Pods running in the cluster, you could navigate to
http://localhost:8080/api/v1/pods or navigate to http://localhost:8080/api/v1/namespaces to see all namespaces.Using this proxy we can also access the
web-frontend service we deployed. So, instead of running a Pod inside the cluster and make cURL requests to the service or Pods, you can create the proxy server and use the following URL to access the service:http://localhost:8080/api/v1/namespaces/default/services/web-frontend:80/proxy/
Note
The URL format to access a service ishttp://localhost:[PORT]/api/v1/namespaces/[NAMESPACE]/services/[SERVICE_NAME]:[SERVICE_PORT]/proxy. In addition to using the service port (e.g.80) you can also name your ports an use the port name instead (e.g.http).
Browsing to the URL above will render the simple HTML site with the
Hello World message.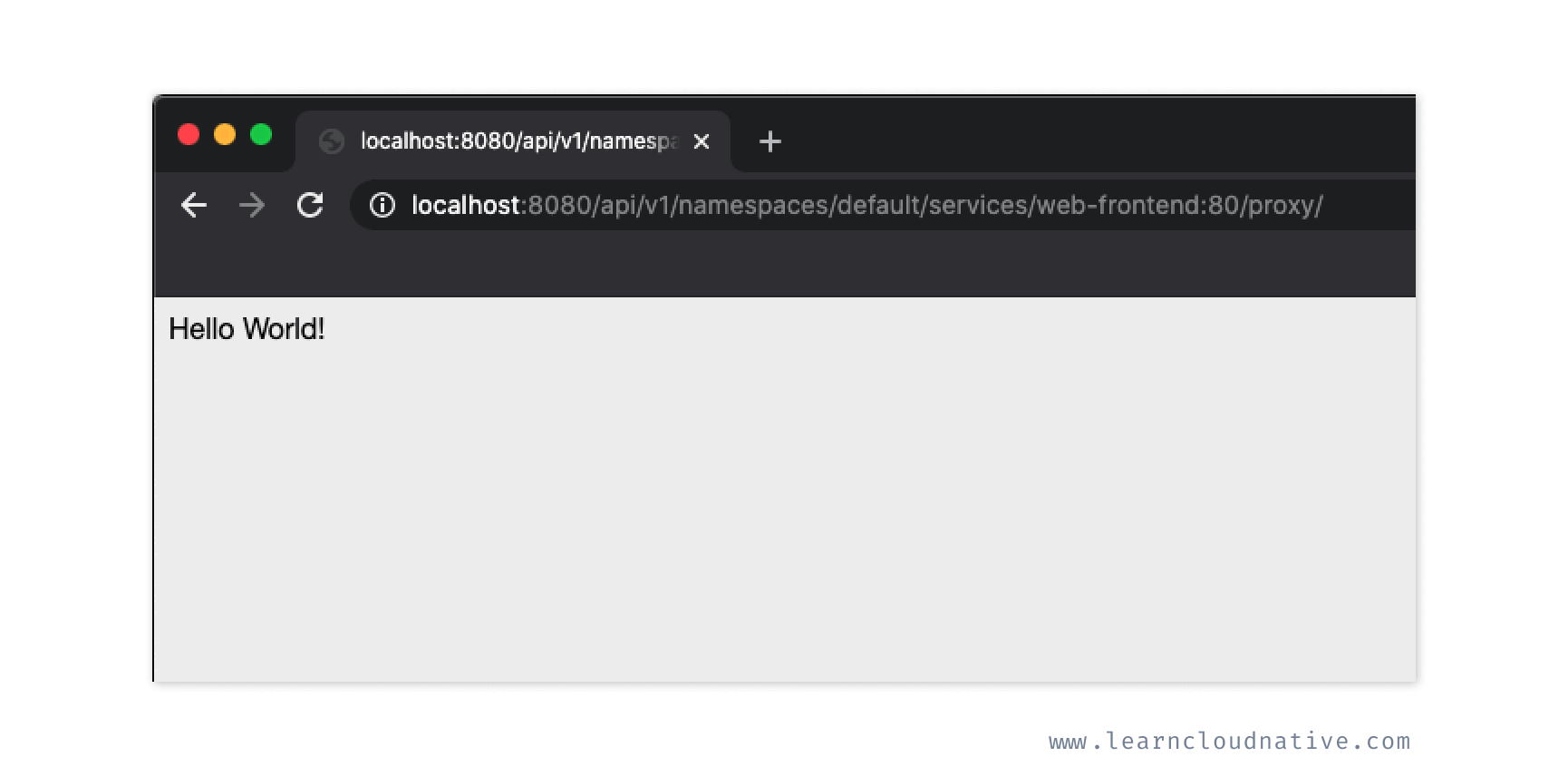
To stop the proxy, you can press CTRL+C in the terminal window.
Viewing service details
Using the
describe command, you can describe an object in Kubernetes and look at its properties. For example, let's take a look at the details of the web-frontend service we deployed:$ kubectl describe svc web-frontend
Name: web-frontend
Namespace: default
Labels: app=web-frontend
Annotations: Selector: app=web-frontend
Type: ClusterIP
IP: 10.100.221.29
Port: http 80/TCP
TargetPort: 3000/TCP
Endpoints: 10.244.0.171:3000,10.244.0.172:3000,10.244.0.173:3000 + 1 more...
Session Affinity: None
Events: <none>
This view gives us more information than the
get command does - it shows the labels, selector, the service type, the IP, and the ports. Additionally, you will also notice the Endpoints. These IP addresses correspond to the IP addresses of the Pods.You can also view endpoints using the
get endpoints command:$ kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 172.18.0.2:6443 8d
web-frontend 10.244.0.171:3000,10.244.0.172:3000,10.244.0.173:3000 + 1 more... 41h
To see the controller that manages these endpoints in action, you can use the
--watch flag to watch the endpoints like this:$ kubectl get endpoints --watch
Then, in a separate terminal window, let's scale the deployment to one pod:
$ kubectl scale deploy web-frontend --replicas=1
deployment.apps/web-frontend scaled
As soon as the deployment is scaled, you will notice how the endpoints get automatically updated. For example, this is how the output looks like when the deployment is scaled:
$ kubectl get endpoints -w
NAME ENDPOINTS AGE
kubernetes 172.18.0.2:6443 8d
web-frontend 10.244.0.171:3000,10.244.0.172:3000,10.244.0.173:3000 + 1 more... 41h
web-frontend 10.244.0.171:3000,10.244.0.172:3000 41h
web-frontend 10.244.0.171:3000 41h
Notice how it went from four Pods, then down to two and finally to one. If you scale the deployment back to four Pods, you will see the endpoints list populated with new IPs.
Kubernetes service types
From the service description output we saw earlier, you might have noticed this line:
Type: ClusterIP
Every Kubernetes Service has a type. If you don't provide a service type, the ClusterIP gets assigned by default. In addition to the ClusterIP, there are three other service types in Kubernetes. These are NodePort, LoadBalancer, and ExternalName.
Let's explain what the differences between these types are.
ClusterIP
The ClusterIP service type is used for accessing Pods from within the cluster through a cluster-internal IP address. In most cases you will use this type of service for your applications running inside the cluster. Using the ClusterIP type you can define the port you want your service to be listening on through the
ports section in the YAML file.Kubernetes assigns a cluster IP to the service. You can then access the service using the cluster IP address and the port you specified in the YAML.
NodePort
At some point you will want to expose your services to the public and allow external traffic to enter your cluster. The NodePort service type opens a specific port on every worker node in your cluster. Any traffic that gets sent to the node IP and the port number will be forwarded to the service and your Pods.
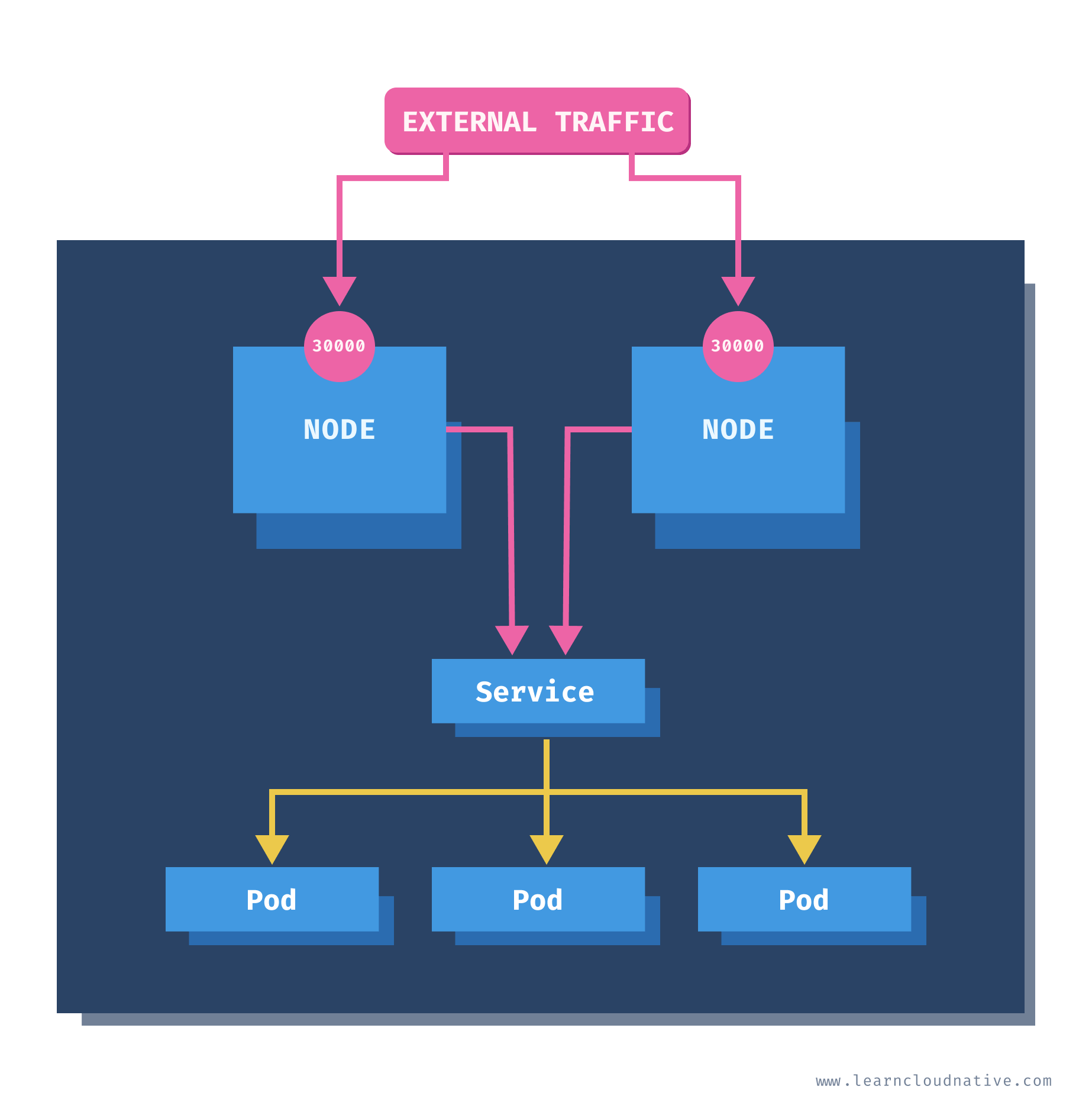
For example if you use the node IP and the port
30000 as shown in the figure above, you will be able to access the service and the Pods.To create a NodePort service you need to specify the service type as shown in the listing below.
kind: Service
apiVersion: v1
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
type: NodePort
selector:
app: web-frontend
ports:
- port: 80
name: http
targetPort: 3000
There's an additional field called
nodePort that can be set under the ports section. However, it is a best practice to leave it out and let Kubernetes pick a port that will be available on all nodes in the cluster. By default, the node port will be allocated between 30000 and 32767 (this is configurable in the API server).You could use the NodePort type when you want to control how the load balancing is done. You can expose your services via NodePort and then configure the load balancer to use the node IPs and node ports. Another scenario where you could use this is if you are migrating an existing solution to Kubernetes for example. In that case you'd probably already have an existing load balancer and you could add the node IPs and node ports to the load balancing pool.
Let's delete the previous
web-frontend service and create one that uses NodePort. To delete the previous service, run kubectl delete svc web-frontend. Then, copy the YAML contents above to the web-frontend-nodeport.yaml file and run kubectl create -f web-frontend-nodeport.yaml OR (if you're on Mac/Linux), run the following command to create the resource directly from the command line:cat <<EOF | kubectl create -f -
kind: Service
apiVersion: v1
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
type: NodePort
selector:
app: web-frontend
ports:
- port: 80
name: http
targetPort: 3000
EOF
Once the service is created, run
kubectl get svc - you will notice the service type has changed and the port number is random as well:$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d
web-frontend NodePort 10.99.15.20 <none> 80:31361/TCP 48m
Now since we are using a local Kubernetes cluster (kind, Minikube, or Docker for Mac/Windows), demonstrating the NodePorts is a bit awkward. We have a single node and the node IPs are private as well. When using a cloud-managed cluster you can set up the load balancer to have access to the same virtual network where your nodes are. Then you can configure it to access the node IPs through the node ports.
Let's get the internal node IP:
$ kubectl describe node | grep InternalIP
InternalIP: 172.18.0.2
Armed with this IP, we can attach to the cURL Pod we have still running, and then cURL to nodes' internal IP and the node port (
31361):$ kubectl attach curl -c curl -i -t
If you don't see a command prompt, try pressing enter.
[ root@curl:/ ]$ curl 172.18.0.2:31361
<link rel="stylesheet" type="text/css" href="css/style.css" />
<div class="container">
Hello World!
</div>
Since we are using Docker for Desktop, we can use
localhost as the node address and the node port to access the service. If you open http://localhost:31361 in your browser, you will be able to access the web-frontend service.LoadBalancer
The LoadBalancer service type is the way to expose Kubernetes services to external traffic. If you are running a cloud-managed cluster and create the Service of the LoadBalancer type, the Kubernetes cloud controller creates an actual Load Balancer in your cloud account.
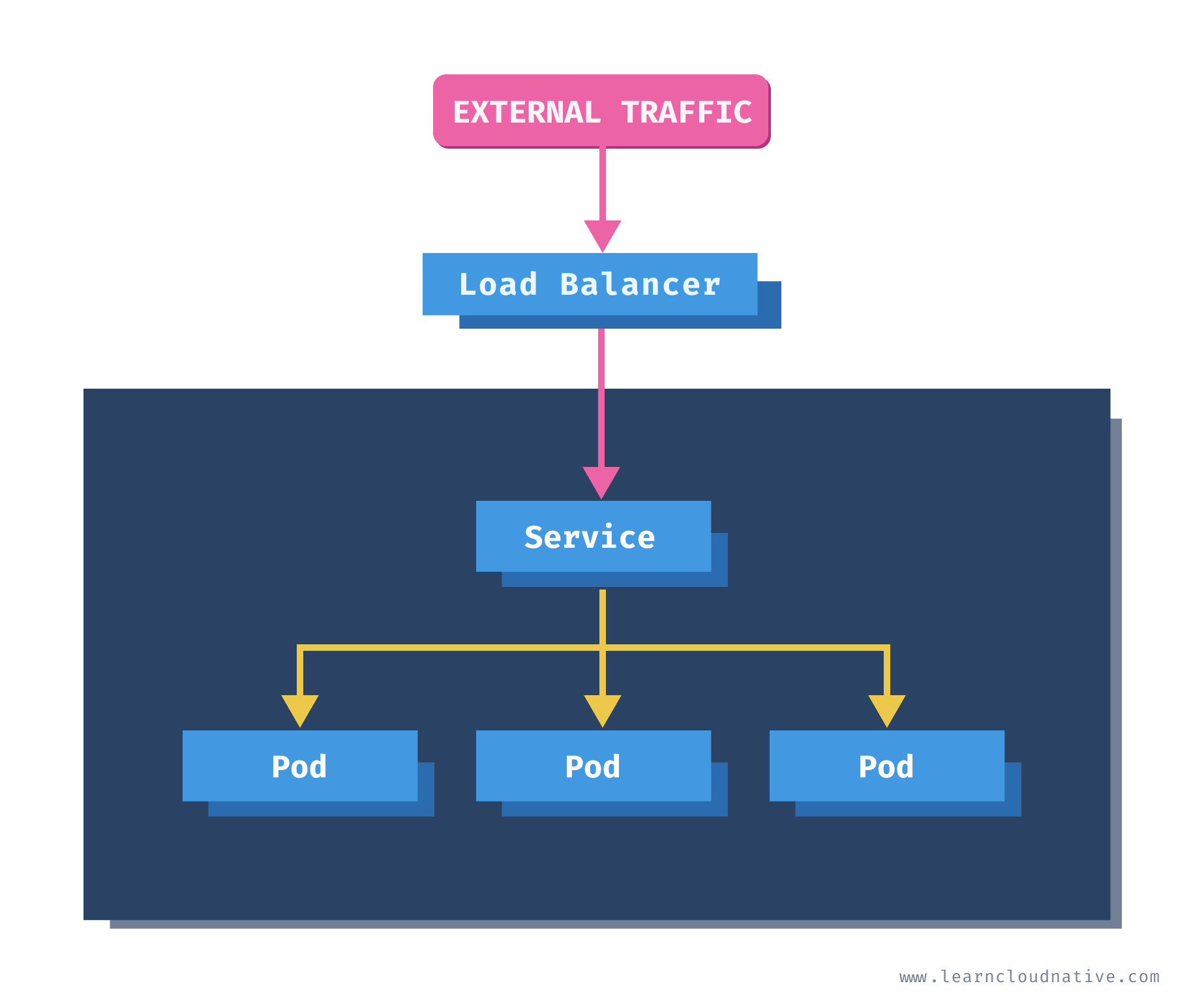
Let's delete the previous NodePort service with
kubectl delete svc web-frontend and create a service that uses the LoadBalancer type:cat <<EOF | kubectl create -f -
kind: Service
apiVersion: v1
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
type: LoadBalancer
selector:
app: web-frontend
ports:
- port: 80
name: http
targetPort: 3000
EOF
If we look at the service now, you'll notice that the type has changed to LoadBalancer and we got an external IP address:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 59d
web-frontend LoadBalancer 10.102.131.150 localhost 80:30832/TCP 2s
Note
When using a cloud-managed Kubernetes cluster, the external IP would be a public, the external IP address you could use to access the service.
If you open
http://localhost or http://127.0.0.1 in your browser, you will be taken to the website running inside the cluster.ExternalName
The ExternalName service type is a special type of a service that does not use selectors. Instead, it uses DNS names.
Using the ExternalName you can map a Kubernetes service to a DNS name. When you make a request to the service it will return the CNAME record with the value in
externalName field, instead of the cluster IP of the service.Here's an example of how ExternalName service would look like:
kind: Service
apiVersion: v1
metadata:
name: my-database
spec:
type: ExternalName
externalName: mydatabase.example.com
You could use the ExternalName service type when migrating workloads to Kubernetes for example. You could keep your database running outside of the cluster, but then use the
my-database service to access it from the workloads running inside your cluster.Conclusion
One thing that's left unanswered: what if I am running multiple applications or websites that I want to expose to the public? Do I use LoadBalancer type for each of those services?
The answer is probably not. Remember that when running a real cluster these load balancers will cost you real money.
However, there is a resource called Ingress that allows you to use a single load balancer (single IP) to direct traffic to multiple services running inside the cluster.
In the second part of this article I will talk about the Ingress resource and show you how to expose multiple applications through a single load balancer - we will deploy multiple websites on the same cluster, see how Ingress can be used to route traffic to them. We will also touch on the subject of application configuration and secrets, and Kubernetes namespaces.
Questions and comments
I am always eager to hear your questions and comments. You can reach me on Twitter or send me a message.
If you are interested in more articles and topics like this one, join over 1000 engineers reading the Learn Cloud Native newsletter.





