
In the previous article, I discussed how local rate limiting in Istio works and how to configure it. At a high level, the difference between local and global rate limiting is in how the rate limit quotas are shared (or not) across instances (Envoy proxies).
For example, if we have a local rate limit of 10 tokens and apply it to a service with five replicas. Each replica gets a quota of 10 tokens. This means you can theoretically send 50 requests before getting rate limited.
On the other hand, the global rate limiter is applied at the service level, regardless of replicas. If we use the same example as before, in this case, we will get rate-limited after ten requests.
I'll focus on the global rate limiting in this article, but reading the previous article might give you a better understanding of the concepts and how they work.
Before diving into the details, we must explain the concepts of actions and descriptors.
Rate limiting actions and descriptors
We can configure a local rate limiter with its token bucket settings as a filter at the top of the HTTP connection manager:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
app: httpbin
version: v1
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
enable_x_ratelimit_headers: DRAFT_VERSION_03
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
The above rate limiter gets applied to all the requests coming to the
httpbin service, regardless of any other request attributes.For a more complex matching of request properties with corresponding rate limits, we can use rate limit actions and rate limit descriptors.
Note that the actions and descriptors are used to overwrite the token bucket settings in the local rate-limiting setup.
For example, if we have a token bucket with 100 tokens per fill, we can use actions/descriptors and overwrite the token bucket settings for that request.
What are rate limit actions and descriptors?
We define rate limit actions at the route level, and they specify the rate limit settings for the route. For each action, if possible, Envoy generates a descriptor entry (a tuple with key and value). As the request goes through the list of actions, Envoy appends the entires in order, and we end up with a list of descriptor entries called a descriptor.
Let's consider the following:
- actions:
- request_headers:
header_name: ":path"
descriptor_key: path
Note
For a complete list of supported rate limit actions, check the Envoy proxy documentation.
As there's only one action in the list, we'll always end up with a single descriptor entry. The entry will be a tuple of the
descriptor_key (e.g. path) and the actual value of the pseudo-header :path. If the request path is /api/v1/hello, the descriptor entry will look like this:("path", "/api/v1/hello")
Every request with a different path will end up with a different descriptor. We define descriptor entries based on the generated descriptor to know which rate limit overwrite to apply. To create a rate limit configuration for the specific path, we can use the following:
- actions:
- request_headers:
header_name: ":path"
descriptor_key: path
...
descriptors:
- entries:
- key: path
value: "/api/v1/hello"
token_bucket:
max_tokens: 500
tokens_per_fill: 20
fill_interval: 30s
So whenever a request comes in, Envoy goes through the actions and creates descriptor entries. For example, if we send a request to
/api/v1/hello the action creates an entry for it. The entry is then matched to the descriptors, and selects the corresponding rate limit configuration.Configuring rate limiting overwrites on different paths is trivial at this point - it just requires adding specific descriptors for a path:
- actions:
- request_headers:
header_name: ":path"
descriptor_key: path
...
descriptors:
- entries:
- key: path
value: "/api/v1/hello"
token_bucket:
max_tokens: 500
tokens_per_fill: 20
fill_interval: 30s
- key: path
value: "/hello"
token_bucket:
max_tokens: 10
tokens_per_fill: 5
fill_interval: 5s
Here's how the full EnvoyFilter configuration would look like for the
/headers and the /ip paths (assuming the httpbin workload):apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: local-rl
namespace: istio-system
spec:
workloadSelector:
labels:
app: httpbin
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
- applyTo: VIRTUAL_HOST
match:
context: SIDECAR_INBOUND
routeConfiguration:
vhost:
name: "inbound|http|8000"
patch:
operation: MERGE
value:
rate_limits:
- actions:
- request_headers:
header_name: ":path"
descriptor_key: path
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_INBOUND
routeConfiguration:
vhost:
name: "inbound|http|8000"
route:
action: ANY
patch:
operation: MERGE
value:
typed_per_filter_config:
envoy.filters.http.local_ratelimit:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 5
tokens_per_fill: 5
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
descriptors:
- entries:
- key: path
value: /headers
token_bucket:
max_tokens: 2
tokens_per_fill: 10
fill_interval: 120s
- entries:
- key: path
value: /ip
token_bucket:
max_tokens: 10
tokens_per_fill: 5
fill_interval: 120s
The above configuration has three parts:
- Inserting the
envoy.filters.http.local_ratelimitfilter in the filter chain - Declaring the rate limit actions at the
VIRTUAL_HOST - Declaring the rate limit descriptors (and rate limiter configuration) at the
HTTP_ROUTE
Note that if neither of the descriptors matches the generated descriptor, the default rate limit configuration is used (configured the same way as we did previously).
Of course, we can add more actions and create a more complex descriptor:
- actions:
- generic_key:
descriptor_value: "basic_rl"
- header_value_match:
descriptor_value: "get"
headers:
- name: ":method"
prefix_match: GET
- request_headers:
header_name: "user"
descriptor_value: "user"
The first action in this list is a
generic_key action, which generates a descriptor entry with the key generic_key and the value basic_rl. Envoy always creates this entry, which we can use as a fallback rate limit configuration.For example, if we had actions that might not generate an entry, we could still have a descriptor matching the generic key and apply that rate limit configuration.
The second action will use a prefix match and check whether the pseudo-header
:method matches the value GET. If it does, an entry with key header_match and value get (descriptor_value) is generated - ("header_match", "get"). If the request method is not GET, Envoy doesn't generate anything.Lastly, we have a
request_headers action that will check whether the request has a header user. If it does, an entry with key user and value of the actual header is generated - ("user", "peterj"). If the header is not present, no entry gets generated.Note the difference between the
header_value_match and the request_header. The former will check whether the header value matches a specific value, while the latter will check whether the header is present and generate an entry with the actual value of the header.Here are the requests and the corresponding descriptors:
GET /api/v1/hello
("generic_key", "basic_rl")
("header_match", "get")
POST /api/v1/something
("generic_key", "basic_rl")
POST -H "user: peterj" /api/v1/hello
("generic_key", "basic_rl")
("user": "peterj")
GET -H "user: peterj" /api/v1/hello
("generic_key", "basic_rl")
("header_match", "get")
("user": "peterj")
Note that depending on the request, we get different descriptors this time. This means that we can configure different rate limit overwrites for each descriptor. For example, we could always configure a rate limit overwrite for whenever the
basic_rl generic key is set (i.e., for all requests). Then we can configure specific rate limit overwrites for GET requests or even rate limits based on the user header value.To configure descriptors to match the above requests, we can group them like this:
- actions:
- generic_key:
descriptor_value: "basic_rl"
- header_value_match:
descriptor_value: "get"
headers:
- name: ":method"
prefix_match: GET
- request_headers:
header_name: "user"
descriptor_value: "user"
...
descriptors:
- entries:
- key: generic_key
value: basic_rl
token_bucket:
max_tokens: 500
tokens_per_fill: 20
fill_interval: 30s
- entries:
- key: generic_key
value: basic_rl
- key: header_match
value: get
token_bucket:
max_tokens: 10
tokens_per_fill: 5
fill_interval: 5s
- entries:
- key: generic_key
value: basic_rl
- key: header_match
value: get
- key: user
value: peterj
token_bucket:
max_tokens: 100
tokens_per_fill: 10
fill_interval: 10s
Global rate limiting and hierarchical descriptors
While we could technically configure the local rate limiter in one place (forget about the three different sections of the EnvoyFilter), we can break the global rate limiter configuration into two parts:
- Client-side configuration (for Envoy proxies) where we define the rate limit actions
- Server-side configuration (with descriptors and quotas), consisting of the dedicated rate limit service and a Redis instance.
The functionality of the global rate limiter is similar to the local rate limiter - for every new connection or an HTTP request, Envoy calls the rate limit service and checks whether the request should be rate-limited or not. The actual quotas and counters get cached in Redis.
At the client side (Envoy proxy), we configure the global rate limiter with rate limit actions. We configure the actions in the same way as the local rate limiter actions. But, instead of configuring the token bucket settings, we configure the rate limit service address and delegate the rate-limiting decision. The snippet below shows the
envoy.filters.http.ratelimit configuration for the global rate limiter:...
http_filters:
- name: envoy.filters.http.ratelimit
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ratelimit.v3.RateLimit
domain: some_domain
enable_x_ratelimit_headers: DRAFT_VERSION_03
rate_limit_service:
transport_api_version: V3
grpc_service:
envoy_grpc:
cluster_name: my-global-ratelimit-cluster
...
Note
Thecluster_namein Envoy is a collection of endpoints (IPs/DNS names) that Envoy can connect to. In Istio, the control plane creates and configures the clusters and endpoints automatically.
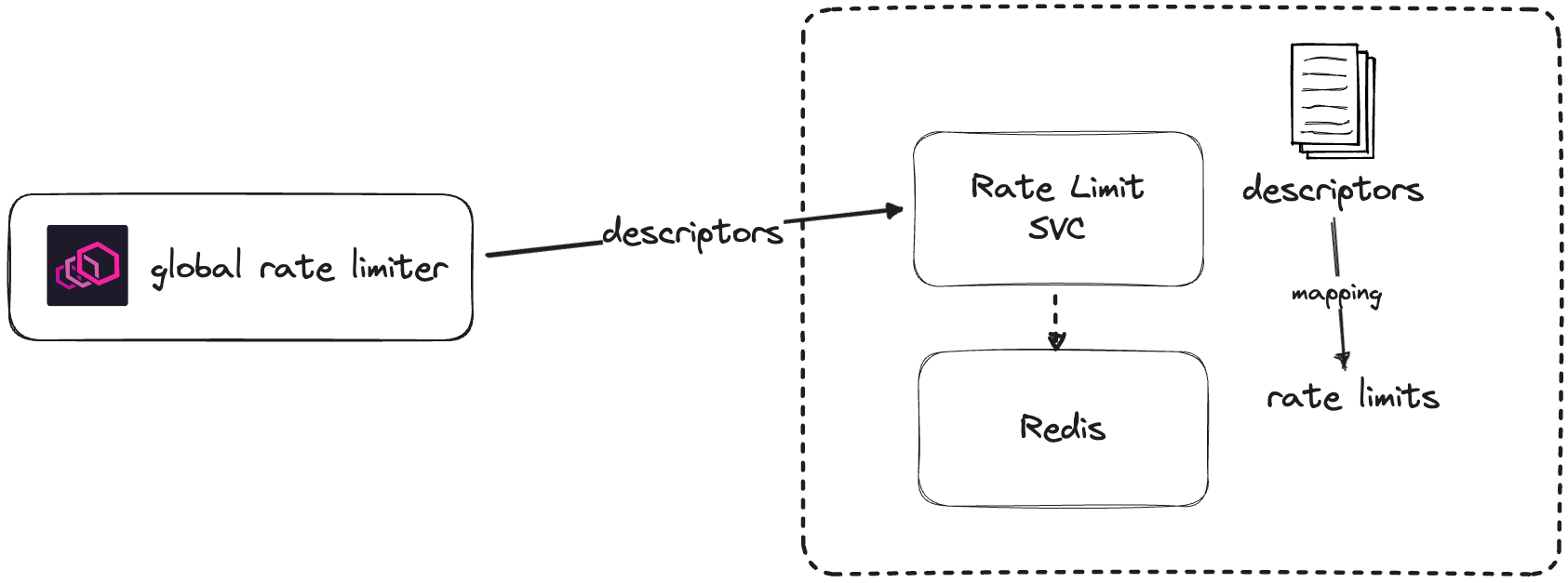
On the server side, we have two parts - the rate limiting service and an instance of Redis to track the rate limits.
The rate limit service is configured with a hierarchical list of descriptors and corresponding quotas. As the requests come into your service, the defined actions create descriptor entries, and the Envoy proxy sends those over to the rate-limiting service. The rate-limiting service tries to match the received descriptors with the configured descriptors, consult with Redis about the actual quotas state, and sends back the information on whether the request should be rate-limited.
Here's an example of the descriptors that are part of the configuration for the rate-limiting service. Note the difference this time is that we can nest the descriptors and create more complex matching:
domain: my_domain
descriptors:
- key: generic_key
value: basic_rl
rate_limit:
unit: MINUTE
requests_per_unit: 10
descriptors:
- key: header_match
value: get
rate_limit:
unit: MINUTE
requests_per_unit: 20
descriptors:
- key: user
value: peterj
rate_limit:
unit: SECOND
requests_per_unit: 25
- key: user
value: jane
rate_limit:
unit: HOUR
requests_per_unit: 10
descriptors:
- key: user
value: peterj
rate_limit:
unit: SECOND
requests_per_unit: 500
- key: user
value: john
rate_limit:
unit: SECOND
requests_per_unit: 50
- key: user
value: jane
rate_limit:
unit: MINUTE
requests_per_unit: 5
Note
Thedomainfield is also new here - it's just a way to group the descriptors and quotas. You can have multiple domains configured in the rate limit service. Just make sure you're referencing the correct one in the EnvoyFilter configuration.
Let's explain how hierarchical matching works with a couple of examples:
| Request | Descriptor | Rate limit |
|---|---|---|
| GET /api/v1/hello | ("generic_key", "basic_rl"), ("header_match", "get") | 20 req/min |
| POST /api/v1/something | ("generic_key", "basic_rl") | 10 req/min |
| POST -H "user: peterj" /api/v1/hello | ("generic_key", "basic_rl"), ("user": "peterj") | 500 req/sec |
| POST -H "user: jane" /api/v1/hello | ("generic_key", "basic_rl"), ("user": "jane") | 5 req/min |
| POST -H "user: john" /api/v1/hello | ("generic_key", "basic_rl"), ("user": "john") | 50 req/min |
| GET -H "user: peterj" /api/v1/hello | ("generic_key", "basic_rl"), ("header_match", "get"), ("user": "peterj") | 25 req/sec |
| GET -H "user: jane" /api/v1/hello | ("generic_key", "basic_rl"), ("header_match", "get"), ("user": "jane") | 10 req/h |
| GET -H "user: john" /api/v1/hello | ("generic_key", "basic_rl"), ("header_match", "get"), ("user": "john") | 20 req/min (header_match) |
Envoy generates descriptors from actions (defined on the client side) and sends them to the rate limit service. The rate limit service tries to match them against the configured descriptors. We configure the actions in the same way as for the local rate-limiting setup we explained earlier.
The thing to note with actions is that they are processed sequentially. If we have multiple actions defined, Envoy will go through them in order, create the descriptor entries and send them to the rate limit service.
Also, if the action doesn't produce a descriptor entry (e.g., header not set, path didn't match, etc.), Envoy will not create a descriptor. The same goes if a single action has multiple sub-actions defined - if one action doesn't match, nothing gets created (AND semantics).
Istio global rate limiter example
Let's look at the global rate limiting in practice. I am using a Kubernetes cluster with Istio 1.18.2 installed (demo profile); I've also installed Prometheus and Grafana from the Istio addons.
As our sample workload, I'll be using
httpbin, running in the default namespace:kubectl label ns default istio-injection=enabled
kubectl apply -f https://raw.githubusercontent.com/istio/istio/master/samples/httpbin/httpbin.yaml
I have also configured the ingress gateway to route to the
httpbin workload as we'll be applying global rate limits at the ingress:apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: gateway
namespace: istio-system
spec:
selector:
app: istio-ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- '*'
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
namespace: default
spec:
hosts:
- '*'
gateways:
- istio-system/gateway
http:
- route:
- destination:
host: httpbin.default.svc.cluster.local
port:
number: 8000
We should be able to access the
httpbin service from outside the cluster:INGRESS_GATEWAY_IP=$(kubectl get svc istio-ingressgateway -n istio-system -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
curl $INGRESS_GATEWAY_IP/headers
{
"headers": {
"Accept": "*/*",
"Host": "<ingress-gateway-ip>",
"User-Agent": "curl/7.88.1",
"X-B3-Parentspanid": "e6e578ac3b0ca57d",
"X-B3-Sampled": "1",
"X-B3-Spanid": "e0540b2a2706d806",
"X-B3-Traceid": "21753e41c389724fe6e578ac3b0ca57d",
"X-Envoy-Attempt-Count": "2",
"X-Envoy-Internal": "true",
"X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/default/sa/httpbin;Hash=cf3e7a69517110b9e360bccbe0bb085538903d88c486f972a78e35c45f1be1bb;Subject=\"\";URI=spiffe://cluster.local/ns/istio-system/sa/istio-ingressgateway-service-account"
}
}
Here's what we're going to do next:
- Deploy Redis
- Come up with a rate limit configuration
- Deploy the rate limit service with the configuration and hook it up with Redis
- Configuring global rate limiter with EnvoyFilter
Deploy Redis
Redis is used to store the rate limit counters. For the sake of simplicity, we'll deploy a single Redis instance inside the cluster. In production, you'd probably want to deploy a Redis cluster, take care of security and all those things. The rate limit service docs discuss different settings and operation modes it supports for Redis.
apiVersion: v1
kind: ServiceAccount
metadata:
name: redis
---
apiVersion: v1
kind: Service
metadata:
name: redis
labels:
app: redis
spec:
ports:
- name: redis
port: 6379
selector:
app: redis
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- image: redis:alpine
imagePullPolicy: Always
name: redis
ports:
- name: redis
containerPort: 6379
restartPolicy: Always
serviceAccountName: redis
You can deploy the above using
kubectl apply.Rate limit configuration
We'll create the rate limit configuration in a ConfigMap that will be mounted and used by the rate-limiting service. One of the typical scenarios for rate limiting is rate limiting based on the remote address. We can use the
remote_address action we'll define later. We'll also use a value from the request header (e.g., user) and configure rate limits based on that.apiVersion: v1
kind: ConfigMap
metadata:
name: ratelimit-config
data:
config.yaml: |
domain: my-ratelimit
descriptors:
- key: remote_address
rate_limit:
unit: minute
requests_per_unit: 5
descriptors:
- key: user
value: peterj
rate_limit:
unit: MINUTE
requests_per_unit: 15
- key: user
value: john
rate_limit:
unit: MINUTE
requests_per_unit: 25
Here's the table showing the relationship between the request, the generated descriptor, and the corresponding rate limit:
| Request | Descriptor | Rate limit |
|---|---|---|
| GET /ip | ("remote_address", "1.0.0.0") | 5 req/min |
| GET -H "user: peterj" /headers | ("remote_address", "1.0.0.0"), ("user": "peterj") | 15 req/min |
| GET -H "user: john" /ip | ("remote_address", "1.0.0.0"), ("user": "peterj") | 25 req/min |
Let's apply the above, and then we can deploy the rate limit service.
apiVersion: v1
kind: Service
metadata:
name: ratelimit
labels:
app: ratelimit
spec:
ports:
- name: http-port
port: 8080
targetPort: 8080
protocol: TCP
- name: grpc-port
port: 8081
targetPort: 8081
protocol: TCP
- name: http-debug
port: 6070
targetPort: 6070
protocol: TCP
selector:
app: ratelimit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ratelimit
spec:
replicas: 1
selector:
matchLabels:
app: ratelimit
strategy:
type: Recreate
template:
metadata:
labels:
app: ratelimit
spec:
containers:
# Latest image from https://hub.docker.com/r/envoyproxy/ratelimit/tags
- image: envoyproxy/ratelimit:e059638d
imagePullPolicy: Always
name: ratelimit
command: ["/bin/ratelimit"]
env:
- name: LOG_LEVEL
value: debug
- name: REDIS_SOCKET_TYPE
value: tcp
- name: REDIS_URL
value: redis.default.svc.cluster.local:6379
- name: USE_STATSD
value: "false"
- name: RUNTIME_ROOT
value: /data
- name: RUNTIME_SUBDIRECTORY
value: ratelimit
- name: RUNTIME_WATCH_ROOT
value: "false"
- name: RUNTIME_IGNOREDOTFILES
value: "true"
ports:
- containerPort: 8080
- containerPort: 8081
- containerPort: 6070
volumeMounts:
- name: config-volume
# $RUNTIME_ROOT/$RUNTIME_SUBDIRECTORY/$RUNTIME_APPDIRECTORY/config.yaml
mountPath: /data/ratelimit/config
volumes:
- name: config-volume
configMap:
name: ratelimit-config
Deploy the above YAML and then check the logs from the pod to ensure the rate limit service is successfully connected to Redis and parsed the configuration.
Here's how the output should look like (notice the
connecting to redis and loading descriptor lines):level=warning msg="statsd is not in use"
level=info msg="Tracing disabled"
level=warning msg="connecting to redis on redis.default.svc.cluster.local:6379 with pool size 10"
level=debug msg="Implicit pipelining enabled: false"
level=debug msg="loading domain: my-ratelimit"
level=debug msg="Creating stats for key: 'my-ratelimit.remote_address'"
level=debug msg="loading descriptor: key=my-ratelimit.remote_address ratelimit={requests_per_unit=5, unit=MINUTE, unlimited=false, shadow_mode=false}"
level=debug msg="Creating stats for key: 'my-ratelimit.remote_address.user_peterj'"
level=debug msg="loading descriptor: key=my-ratelimit.remote_address.user_peterj ratelimit={requests_per_unit=15, unit=MINUTE, unlimited=false, shadow_mode=false}"
level=debug msg="Creating stats for key: 'my-ratelimit.remote_address.user_john'"
level=debug msg="loading descriptor: key=my-ratelimit.remote_address.user_john ratelimit={requests_per_unit=25, unit=MINUTE, unlimited=false, shadow_mode=false}"
Even though we haven't applied the global rate limiter to any of the workloads, we can still test the rate limit service by directly invoking the rate limit service on port 8080 and sending requests to the
/json endpoint.Note
Port 6070 can be used for debugging (e.g., printing out the service stats, config, etc.).
Let's port-forward to the
ratelimit service on port 8080 and send a couple of requests to validate our configuration.kubectl port-forward svc/ratelimit 8080:8080 &
The
/json endpoint expects the requests in this format:{
"domain": "my-ratelimit",
"descriptors": [{ "entries": [{ "key": "<somekey>", "value": "<somevalue>" }, { "key": "<anotherkey>", "value": "<anothervalue>" }] }]
}
Let's test the results for the scenario where we aren't setting any headers, so the only descriptor that will be used is the one with the
remote_address key. Note that the remote_address will be filled out automatically by Envoy with the client's IP address.curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "remote_address", "value": "10.0.0.0"}] }]}'
{
"overallCode": "OK",
"statuses": [
{
"code": "OK",
"currentLimit": {
"requestsPerUnit": 5,
"unit": "MINUTE"
},
"limitRemaining": 4,
"durationUntilReset": "2s"
}
]
}
The service responds with the above JSON that tells us the request is not rate-limited and shows us which rate-limit configuration was used. The
limitRemaining field tells us how many requests we have left until the next reset. In our case, it shows we have four requests left which comes from the quote of the first descriptor:- key: remote_address
rate_limit:
unit: minute
requests_per_unit: 5
If we go above the limit by sending more than five requests per minute, we'll get the following response telling us we're over the limit and when the limit will reset.
{
"overallCode": "OVER_LIMIT",
"statuses": [
{
"code": "OVER_LIMIT",
"currentLimit": {
"requestsPerUnit": 5,
"unit": "MINUTE"
},
"durationUntilReset": "21s"
}
]
}
Since this configuration uses the
remote_address, we can send a request with a different address, and we'll see that each IP gets its quota.Depending on where your Kubernetes cluster is running, make sure you set the external traffic policy on the ingress gateway, so the remote address used is the client's IP address and not the ingress gateway pods IP.
You can patch your deployment and set the
externalTrafficPolicy like this:kubectl patch svc istio-ingressgateway -n istio-system -p '{"spec":{"externalTrafficPolicy":"Local"}}'
The second scenario to test is setting the
user header to peterj:curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "remote_address", "value": "10.0.0.0"}, { "key": "user", "value": "peterj"}] }]}'
Notice the rate limit service selected the 15 req/min quota, because we sent two descriptors:
{
"overallCode": "OK",
"statuses": [
{
"code": "OK",
"currentLimit": {
"requestsPerUnit": 15,
"unit": "MINUTE"
},
"limitRemaining": 14,
"durationUntilReset": "60s"
}
]
}
Similarly, if we send another request with the header
user: john, we can confirm the service uses the 25 req/min quota.Let's create another, more complex configuration with the following rate limits:
- Rate limit for each unique IP address for 10 req/min - this is the rate limit we always want to apply, even if none of the other limits match
- Rate limit on
/ippath for 100 req/min - Rate limit on
/headerspath for 50 req/min- If the user is
peterjwe'll allow only 35 req/min
- If the user is
This time, we'll start by coming up with the action's configuration first:
# Action 1
- actions:
# Always created (we're assuming xff header is set). ("remote_address", "10.0.0.0")
- remote_address: {}
# Action 2
- actions:
# Match on path prefix "/ip" ("header_match", "ip_path")
- header_value_match:
descriptor_value: "ip_path"
headers:
- name: :path
prefix_match: /ip
# Action 3
- actions:
# Match on path prefix "/headers" ("header_match", "headers_path")
- header_value_match:
descriptor_value: "headers_path"
headers:
- name: :path
prefix_match: /headers
# Action 4
- actions:
# Match on path prefix "/headers" ("header_match", "headers_path")
- header_value_match:
descriptor_value: "headers_path"
headers:
- name: :path
prefix_match: /headers
# Match on `user` header (if set, "user", "<value_from_the_header>")
- request_headers:
header_name: "user"
descriptor_key: "user"
| Request | Action 1 entry | Action 2 entry | Action 3 entry | Action 4 entry | Descriptor | | --- | --- | --- | --- | --- | |
GET / | ("remote_address": "10.0.0.0") | - | - | - | ("remote_address": "10.0.0.0") | | GET /ip | ("remote_address": "10.0.0.0") | ("header_match": "ip_path") | - | - | ("remote_address": "10.0.0.0"), ("header_match": "ip_path") | | GET /headers | ("remote_address": "10.0.0.0") | - | ("header_match": "headers_path") | - (both action have to evaluate to True, otherwise no entry gets created)| ("remote_address": "10.0.0.0"), ("header_match": "headers_path") | | GET -H "user: peterj" /headers | ("remote_address": "10.0.0.0") | - | ("header_match": "headers_path") | ("header_match": "headers_path"), ("user": "peterj") | ("remote_address": "10.0.0.0"), ("header_match": "headers_path"), ("header_match": "headers_path") ("user": "peterj") |Based on the above table, we can create the configuration that will match the requests to the correct rate limit:
apiVersion: v1
kind: ConfigMap
metadata:
name: ratelimit-config
data:
config.yaml: |
domain: my-ratelimit
descriptors:
# Any descriptor with the remote address set, gets a rate limit of 10 req/min
- key: remote_address
rate_limit:
unit: minute
requests_per_unit: 100
# Any descriptor with /ip path
- key: header_match
value: ip_path
rate_limit:
unit: MINUTE
requests_per_unit: 10
# Any descriptor with /headers path
- key: header_match
value: headers_path
rate_limit:
unit: MINUTE
requests_per_unit: 50
# Any descriptor with /headers path AND user header set to peterj
descriptors:
- key: user
value: peterj
rate_limit:
unit: MINUTE
requests_per_unit: 35
The thing to note above is the nested descriptor - we're setting a rate limit when the path is
/headers, but if there's also a users header set to peterj we're setting a different rate limit (35 req/min). If we don't provide the user header, Envoy won't create the descriptor and the rate limit will be 50 req/min (because we have a separate action generating the descriptor for the /headers path only).Apply the above
ratelimit-config and restart the ratelimit service: kubectl rollout restart deploy ratelimit.Let's try the rate limit quotas:
curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "remote_address", "value": "10.0.0.0"}] }]}'
# Result:
# {"overallCode":"OK","statuses":[{"code":"OK","currentLimit":{"requestsPerUnit":100,"unit":"MINUTE"},"limitRemaining":9,"durationUntilReset":"18s"}]}
curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "header_match", "value": "ip_path"}] }]}'
# Result:
# {"overallCode":"OK","statuses":[{"code":"OK","currentLimit":{"requestsPerUnit":10,"unit":"MINUTE"},"limitRemaining":99,"durationUntilReset":"45s"}]}
curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "header_match", "value": "headers_path"}] }]}'
# Result:
# {"overallCode":"OK","statuses":[{"code":"OK","currentLimit":{"requestsPerUnit":50,"unit":"MINUTE"},"limitRemaining":49,"durationUntilReset":"15s"}]}
curl localhost:8080/json -d '{"domain": "my-ratelimit", "descriptors": [{ "entries": [{ "key": "header_match", "value": "headers_path"}, { "key": "user", "value": "peterj"}] }]}'
# Result:
# "overallCode":"OK","statuses":[{"code":"OK","currentLimit":{"requestsPerUnit":35,"unit":"MINUTE"},"limitRemaining":34,"durationUntilReset":"49s"}]}%
Let's go and configure a global rate limiter with Istio, all running inside a Kubernetes cluster.
Configuring global rate limiter with EnvoyFilter
When configuring the global rate limiter on the client side, we need to tell the Envoy proxy where to find the rate limit service, define the actions that are created, and then send them to the rate limit service.
We'll start by configuring the Envoy RateLimit filter and pointing it to the rate limit service cluster name. We can use the
istioctl proxy-config cluster command to get the cluster name.We know the FQDN of the Kubernetes service (
ratelimit.default.svc.cluster.local) and the gRPC port number (8081), so we can use the following command to find the cluster name:istioctl pc cluster deploy/httpbin --fqdn ratelimit.default.svc.cluster.local --port 8081 -o json | grep serviceName
"serviceName": "outbound|8081||ratelimit.default.svc.cluster.local"
The value
outbound|8081||ratelimit.default.svc.cluster.local is the cluster name we can use to reference the rate limit service.Here's the first EnvoyConfig:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
istio: ingressgateway
configPatches:
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
subFilter:
name: 'envoy.filters.http.router'
patch:
operation: INSERT_BEFORE
value:
# Configure the ratelimit filter
name: envoy.filters.http.ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
# Updated type_url
type_url: type.googleapis.com/envoy.extensions.filters.http.ratelimit.v3.RateLimit
value:
# Note that this has to match the domain in the ratelimit ConfigMap
domain: my-ratelimit
enable_x_ratelimit_headers: DRAFT_VERSION_03
timeout: 5s
failure_mode_deny: true
rate_limit_service:
grpc_service:
envoy_grpc:
cluster_name: outbound|8081||ratelimit.default.svc.cluster.local
authority: ratelimit.default.svc.cluster.local
transport_api_version: V3
Next, we have to tell Envoy to generate the descriptor entries and define the actions. We'll apply the EnvoyFilter to the virtual host configuration and merge in the rate limit actions:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-rl-actions
namespace: istio-system
spec:
workloadSelector:
labels:
istio: ingressgateway
configPatches:
- applyTo: VIRTUAL_HOST
match:
context: GATEWAY
routeConfiguration:
vhost:
name: ""
route:
action: ANY
patch:
operation: MERGE
value:
rate_limits:
# Action 1
- actions:
# Always created (we're assuming xff header is set). ("remote_address", "10.0.0.0")
- remote_address: {}
# Action 2
- actions:
# Match on path prefix "/ip" ("header_match", "ip_path")
- header_value_match:
descriptor_value: "ip_path"
headers:
- name: :path
prefix_match: /ip
# Action 3
- actions:
# Match on path prefix "/headers" ("header_match", "headers_path")
- header_value_match:
descriptor_value: "headers_path"
headers:
- name: :path
prefix_match: /headers
# Action 4
- actions:
# Match on path prefix "/headers" ("header_match", "headers_path")
- header_value_match:
descriptor_value: "headers_path"
headers:
- name: :path
prefix_match: /headers
# Match on `user` header (if set, "user", "<value_from_the_header>")
- request_headers:
header_name: "user"
descriptor_key: "user"
At this point, we can apply both EnvoyFilters and then try them out!
For example, if we send a request to
curl -v $INGRESS_GATEWAY_IP/ip more than ten times, we'll get rate-limited and receive a response like this:* Trying <INGRESS_GATEWAY_IP>...
* Connected to ----- (----) port 80 (#0)
> GET /ip HTTP/1.1
> Host: ----
> User-Agent: curl/7.88.1
> Accept: */*
>
< HTTP/1.1 429 Too Many Requests
< x-envoy-ratelimited: true
< server: istio-envoy
< content-length: 0
We can also take a look at the logs from the rate-limit service to see the details about which rate limits are being looked up and applied.
Similarly, if we send a request to the
/headers endpoint we'll see in the response headers the quota rate limit service selected:< HTTP/1.1 200 OK
< server: istio-envoy
...
< x-envoy-upstream-service-time: 1
< x-ratelimit-limit: 35, 100;w=60, 50;w=60, 35;w=60
< x-ratelimit-remaining: 33
< x-ratelimit-reset: 20
...
Note the
x-ratelimit-limit header showing that the quota selected was the one with 35 requests per minute. We can also remove x-ratelimit headers by deleting the enable_x_ratelimit_headers: DRAFT_VERSION_03 from the EnvoyFilter config.Metrics
The rate limit service creates metrics that we can consume. We'll use
statsd-exporter to translate the StatsD metrics into Prometheus metrics.First, let's create the configuration that defines the mapping rules (note that this is from the rate limit service repo):
apiVersion: v1
kind: ConfigMap
metadata:
name: statsd-config
data:
statsd.yaml: |
mappings:
- match: "ratelimit.service.rate_limit.*.*.near_limit"
name: "ratelimit_service_rate_limit_near_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
- match: "ratelimit.service.rate_limit.*.*.over_limit"
name: "ratelimit_service_rate_limit_over_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
- match: "ratelimit.service.rate_limit.*.*.total_hits"
name: "ratelimit_service_rate_limit_total_hits"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
- match: "ratelimit.service.rate_limit.*.*.within_limit"
name: "ratelimit_service_rate_limit_within_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
- match: "ratelimit.service.rate_limit.*.*.*.near_limit"
name: "ratelimit_service_rate_limit_near_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
key2: "$3"
- match: "ratelimit.service.rate_limit.*.*.*.over_limit"
name: "ratelimit_service_rate_limit_over_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
key2: "$3"
- match: "ratelimit.service.rate_limit.*.*.*.total_hits"
name: "ratelimit_service_rate_limit_total_hits"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
key2: "$3"
- match: "ratelimit.service.rate_limit.*.*.*.within_limit"
name: "ratelimit_service_rate_limit_within_limit"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
key2: "$3"
- match: "ratelimit.service.call.should_rate_limit.*"
name: "ratelimit_service_should_rate_limit_error"
match_metric_type: counter
labels:
err_type: "$1"
- match: "ratelimit_server.*.total_requests"
name: "ratelimit_service_total_requests"
match_metric_type: counter
labels:
grpc_method: "$1"
- match: "ratelimit_server.*.response_time"
name: "ratelimit_service_response_time_seconds"
observer_type: histogram
labels:
grpc_method: "$1"
- match: "ratelimit.service.config_load_success"
name: "ratelimit_service_config_load_success"
match_metric_type: counter
- match: "ratelimit.service.config_load_error"
name: "ratelimit_service_config_load_error"
match_metric_type: counter
- match: "ratelimit.service.rate_limit.*.*.*.shadow_mode"
name: "ratelimit_service_rate_limit_shadow_mode"
observer_type: "histogram"
labels:
domain: "$1"
key1: "$2"
key2: "$3"
We can apply the above ConfigMap and then create the Deployment and Service for statsd-exporter:
apiVersion: apps/v1
kind: Deployment
metadata:
name: statsd-exporter
spec:
replicas: 1
selector:
matchLabels:
app: statsd-exporter
template:
metadata:
annotations:
prometheus.io/port: "9102"
prometheus.io/scrape: "true"
labels:
app: statsd-exporter
spec:
containers:
- name: statsd-exporter
image: prom/statsd-exporter:v0.24.0
args:
- --statsd.mapping-config=/etc/statsd.yaml
- --statsd.listen-udp=:9125
- --statsd.listen-tcp=:9125
- --web.listen-address=:9102
- --log.level=debug
volumeMounts:
- mountPath: /etc/statsd.yaml
subPath: statsd.yaml
name: statsd-config
readOnly: true
ports:
- containerPort: 9125
protocol: UDP
- containerPort: 9125
protocol: TCP
- containerPort: 9102
protocol: TCP
terminationGracePeriodSeconds: 300
volumes:
- name: statsd-config
configMap:
name: statsd-config
---
apiVersion: v1
kind: Service
metadata:
name: statsd-exporter
spec:
ports:
- name: ingress-tcp
port: 9125
protocol: TCP
targetPort: 9125
- name: ingress-udp
port: 9125
protocol: UDP
targetPort: 9125
selector:
app: statsd-exporter
type: ClusterIP
Let's wait for the statsd-exporter pod to be ready. Once it is ready, we must update the rate limit service and point to this statsd-explorer instance. We'll do that by re-deploying the rate limit service (you could also edit the Deployment directly and add the
STATSD_* environment variables):apiVersion: apps/v1
kind: Deployment
metadata:
name: ratelimit
spec:
replicas: 1
selector:
matchLabels:
app: ratelimit
strategy:
type: Recreate
template:
metadata:
labels:
app: ratelimit
spec:
containers:
# Latest image from https://hub.docker.com/r/envoyproxy/ratelimit/tags
- image: envoyproxy/ratelimit:e059638d
imagePullPolicy: Always
name: ratelimit
command: ["/bin/ratelimit"]
env:
- name: LOG_LEVEL
value: debug
- name: REDIS_SOCKET_TYPE
value: tcp
- name: REDIS_URL
value: redis.default.svc.cluster.local:6379
# BEGIN CHANGES -- CONFIGURE STATSD
- name: USE_STATSD
value: "true"
- name: STATSD_HOST
value: statsd-exporter.default.svc.cluster.local
- name: STATSD_PORT
value: "9125"
# END CHANGES
- name: RUNTIME_ROOT
value: /data
- name: RUNTIME_SUBDIRECTORY
value: ratelimit
- name: RUNTIME_WATCH_ROOT
value: "false"
- name: RUNTIME_IGNOREDOTFILES
value: "true"
ports:
- containerPort: 8080
- containerPort: 8081
- containerPort: 6070
volumeMounts:
- name: config-volume
# $RUNTIME_ROOT/$RUNTIME_SUBDIRECTORY/$RUNTIME_APPDIRECTORY/config.yaml
mountPath: /data/ratelimit/config
volumes:
- name: config-volume
configMap:
name: ratelimit-config
We can look at the logs from the statsd-exporter pod while we send a couple of request to the httpbin service. You should see the metrics captured by statsd-exporter:
...
ts=2023-07-28T22:38:05.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit_server.ShouldRateLimit.response_time:1|ms
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit_server.ShouldRateLimit.total_requests:1|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.service.rate_limit.my-ratelimit.remote_address.total_hits:1|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.service.rate_limit.my-ratelimit.remote_address.within_limit:1|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.totalAlloc:34080|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.mallocs:739|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.frees:36|c
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.sys:0|g
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.heapSys:7340032|g
ts=2023-07-28T22:38:06.100Z caller=listener.go:136 level=debug msg="Incoming line" proto=tcp line=ratelimit.go.heapReleased:2359296|g
Note the
line=ratelimit.service.rate_limit.my-ratelimit.remote_address.total_hits:1|c line above.Since we have Prometheus already installed and because we have the
annotations on the statsd-exporter service, we can already see the metrics in Prometheus. - job_name: statsd-exporter
scrape_interval: 5s
static_configs:
- targets:
- statsd-exporter.default.svc.cluster.local:9102
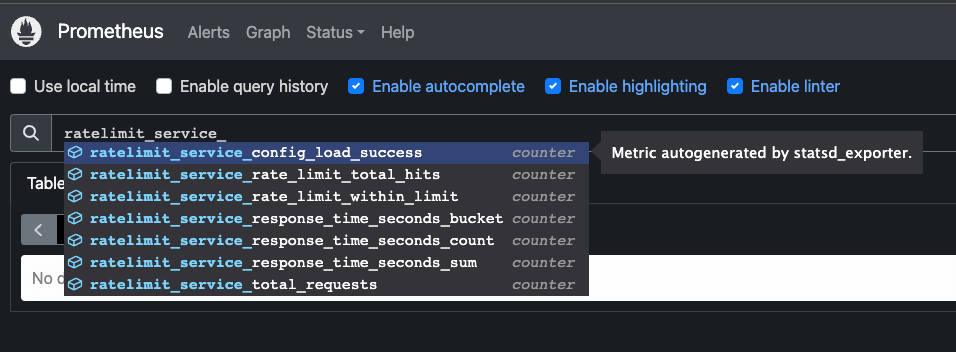
The exported metrics start with
ratelimit_service_* name (for example ratelimit_service_rate_limit_within_limit) and include the metrics such as:total_hits= total number of requests madeover_limit= number of requests that were over the limitnear_limit= number of requests we can make before hitting the near limit ratio (80% of the total limit)within_limit= number of requests that were within the limit
For a full list of emitted metrics, check the
manager.go file from the rate limit service repo.The fact that we get metrics in Prometheus means we can create a Grafana dashboard to visualize the metrics, as shown in the screenshot below.
Note
Note: Clearly, I am far from being proficient with Grafana. If you are experienced with Grafana and willing to build proper dashboards that make sense, let me know!
Conclusion
This was a long one and I still feel there are different settings and configurations I haven't talked about. Thanks for getting all the way to the end. If you found this useful, please share it with your colleagues. If you have any questions, please reach out to me on Twitter or join the growing Discord community.
Related reading:





