
In this article, you'll learn how to configure rate limiting on ingress and egress gateways using Istio.
Currently, Istio doesn't have a dedicated Custom Resource Definition (CRD) that we could use to configure rate limiting. However, since rate limit features are part of the Envoy proxy (which is used in Istio), we can configure the rate limiter using the EnvoyFilter CRD.
Note that enabling the rate limiting on workloads inside the cluster or at the edge with ingress/egress gateways is more-or-less the same. The difference is only in the context to which the EnvoyFilter patch gets applied.
Feel free to skip over the "theoretical" part that explains what is rate limiting and the difference between the local and global rate limiting that's supported in the Envoy proxy, and jump straight to the practical part that shows you how to configure rate limiting.
What is rate limiting?
Rate limiting is a mechanism that allows you to limit the number of requests sent to a service. It specifies the maximum number of requests a client can send to a service in a given period. It's expressed as a number of requests in a period of time - for example, 100 requests per minute or 5 requests per second, and so on.
The purpose of rate limiting is to prevent a service from being overloaded with requests, either from the same client IP or globally, from any client.
If we take an example of 100 requests per minute and send 101 requests to a service, the rate limiter will reject the 101st request. The rate limiter will return a 429 HTTP status code (Too Many Requests) and reject the request before it reaches the service.
Local vs. global rate limiting
Envoy implements rate limiting in two different ways:
- global (or distributed) rate limiting
- local rate limiting
Global rate limiting allows you to rate limit requests across multiple services - or since we're talking about Istio, across the entire mesh. The global rate limiting is implemented using a central rate limiting service that's shared by all the services in the cluster. The rate-limiting service requires an external component, typically a Redis database.
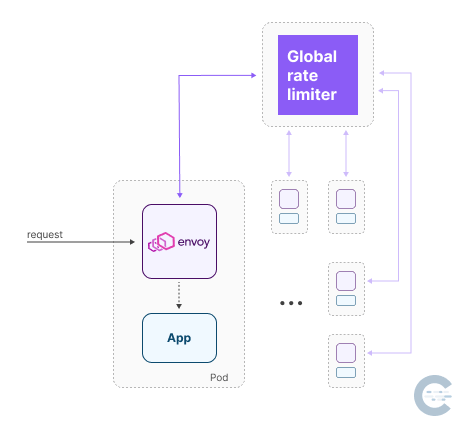
For example, imagine we have a database and multiple clients deployed in the cluster. We can configure a global rate limiter on the database with a limit of 100 requests per minute. Regardless of which client makes a request to the database, the rate limiter will count the number of requests, and if the limit is reached, it will reject the request.
On the other hand, the local rate limiting gets configured on a per Envoy process basis. If we translate this to Istio and Kubernetes world, the "per Envoy process" means per each Pod that has an Envoy proxy injected.
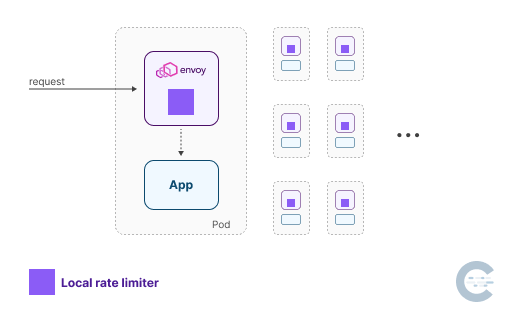
The local rate limiter is simpler to configure, and there's no need for additional components (such as a dedicated rate limit service and Redis for the global rate limiting).
If we take the same example as above, we can configure a local rate limiter, in addition to the existing global one, with a limit of 50 requests per minute for specific client IPs. If that client makes more than 50 requests, the rate limiter will reject the request, even though the global rate limiter hasn't reached the limit.
Note that if there are multiple replicas, each of those replicas will have its own rate limiter - i.e., if you get rate limited on one replica, you might not get rate limited on another replica.
When using both rate limiters, the local rate limit is applied first, and if the limit is not reached, the global rate limiter is applied.
Note
The typical use case for the global rate limiter is when many hosts send requests to a smaller number of services. In this case, the numerous hosts can overwhelm the services, and the global rate limiter can help to prevent cascading failures. For example, we can configure a global rate limiter at the ingress gateway and control the total number of requests entering the mesh. Then, once those requests are inside the mesh, we can use local rate limiters to manage the number of requests sent to specific services.
How does the local rate limiter work?
Envoy implements local rate limiting using a token bucket algorithm. The token bucket algorithm is a way to limit the number of requests that are sent to a service. It's based on the concept of a bucket that contains a certain number of tokens. The bucket keeps getting filled with tokens at a constant rate and when a request is sent to the service, a token is removed from the bucket. If the bucket is empty, the request gets rejected.

To configure the rate limiter, we need to specify the following:
- the maximum number of tokens the bucket can hold
- the rate at which the bucket gets filled (fill interval)
- the number of tokens that get added to the bucket with each fill interval
For example, if we have a bucket with a capacity of 1000 tokens, a fill rate of 10 seconds with 100 tokens per fill. The bucket gets filled with 100 tokens every 10 seconds, up to the maximum of 1000 tokens. If we send 1000 requests to the service (i.e., use up each token in the bucket), the bucket empties, and the rate limiter rejects the 1001st request. After 10 seconds, there will be 100 tokens in the bucket; if we wait long enough (100 seconds), the bucket refills again.
By default, Envoy sends an HTTP 429 response when the rate limiter rejects a request and sets the
x-envoy-ratelimited response header. However, we can configure the rate limiter to return a custom HTTP status code and configure additional response headers.The other terms to understand with the rate limiter are enabling and enforcing the rate limiter.
Enabling the rate limiter means that we're configuring it, but the rate limiter is not applied to the requests.
Enforcing the rate limiter means applying or enforcing the rate limiter on the requests.
We express both values as percentages of incoming requests. For example, we can enable the rate limiter for 10% of the requests and enforce it for 5% of the requests. This gives us a way to gradually roll out the rate limiter and test it before we enforce it for all the requests.
Local rate limiter example
Let's dive into an example and learn how to configure a local rate limiter. I'll be using Istio 1.5.0 and a Kubernetes cluster running on GCP. You'll need something similar if you want to follow along.
When installing Istio, make sure you use the
demo profile to get the egress gateway installed as well. I've also installed Prometheus, Grafana, and Zipkin.istioctl install --set profile=demo -y
Here's what I have:
$ istioctl version
client version: 1.15.0
control plane version: 1.15.0
data plane version: 1.15.0 (2 proxies)
$ kubectl get po -n istio-system
NAME READY STATUS RESTARTS AGE
istio-egressgateway-6854f6dc6f-gz6v6 1/1 Running 0 66s
istio-ingressgateway-7c7c7b5bf9-nppw8 1/1 Running 0 66s
istiod-857cb8c78d-gnph2 1/1 Running 0 82s
To keep things simple, I'll deploy the
httpbin application and then use a curl Pod inside the cluster to test things out. Before deploying, make sure you add the istio-injection=enabled label to the namespace!$ kubectl get ns --show-labels
NAME STATUS AGE LABELS
default Active 15m istio-injection=enabled,kubernetes.io/metadata.name=default
istio-system Active 4m28s kubernetes.io/metadata.name=istio-system
kube-node-lease Active 15m kubernetes.io/metadata.name=kube-node-lease
kube-public Active 15m kubernetes.io/metadata.name=kube-public
kube-system Active 15m kubernetes.io/metadata.name=kube-system
$ kubectl apply -f https://raw.githubusercontent.com/istio/istio/master/samples/httpbin/httpbin.yaml
serviceaccount/httpbin created
service/httpbin created
deployment.apps/httpbin created
$ kubectl get po
NAME READY STATUS RESTARTS AGE
httpbin-74fb669cc6-q4jhj 2/2 Running 0 79s
As mentioned, the rate limiter functionality exists in the Envoy proxy, but it's not exposed through a dedicated Istio resource. Instead, we can use the EnvoyFilter CRD to configure the rate limiter.
Let's look at the Envoy configuration first:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
enable_x_ratelimit_headers: DRAFT_VERSION_03
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
Albeit verbose, the above configuration is pretty straightforward. We're configuring the rate limiter to have a bucket with a capacity of 50 tokens (
max_tokens), and a fill rate of 10 tokens (tokens_per_fill) every 2 minutes (fill_interval). We're also enabling the rate limiter (filter_enabled) for 100% of the requests and enforcing (filter_enforced) it for 100% of the requests. We are also setting a stat_prefix which is used to generate metrics. The enable_x_ratelimit_headers option is used to enable the sending of the response headers that show the rate limit status. By default, the headers are disabled.When configuring the rate limiter using the EnvoyFilter we need to know where the filter should be inserted in the Envoy configuration. From the Envoy documentation, we know that the local rate limit is an HTTP filter, and because of that, it needs to in the list of HTTP filters in the HTTP Connection Manager (HCM).
Here's what the EnvoyFilter for the
httpbin workload might look like:apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
app: httpbin
version: v1
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
enable_x_ratelimit_headers: DRAFT_VERSION_03
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
Note
We're deploying the EnvoyFilter in theistio-system, global, namespace. This means the EnvoyFilter will be applied to any workloads in the mesh that match the workload selector.
There are three key sections of the EnvoyFilter above:
- Workload selector (
workloadSelector)Workload selector used to select the workload to which the EnvoyFilter should be applied. In this case, we're choosing thehttpbinworkload by the app and version labels. - Apply to (
applyTo) & match sections (match)TheapplyTosection tells Istio where we want to apply the patch to. We're using theHTTP_FILTERvalue, specifying theSIDECAR_INBOUNDcontext (i.e., only apply the configuration changes for the inbound requests to the sidecar), and specifying a match on the specific filter (http_connection_manager). These lines will "select" thehttp_filterssection in the Envoy configuration and allow us to either apply a patch to an existing filter or insert a new one. - The patch (
patch)Thepatchsection is where we specify the actual configuration changes. We're using theINSERT_BEFOREoperation to insert the rate limiter filter at the top of the HTTP filter list.
We've configured this rate limiter to apply to all routes and virtual hosts. We could modify that and apply the rate limiter only to specific routes. To do that, we'd have to apply the EnvoyFilter to a particular virtual hostname. We'll show how to do that later in the article when configuring the rate limiter on an egress gateway.
If we apply the EnvoyFilter, the resulting Envoy configuration will look like this:
...
"http_filters": [
{
"name": "envoy.filters.http.local_ratelimit",
"typed_config": {
"@type": "type.googleapis.com/udpa.type.v1.TypedStruct",
"type_url": "type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit",
"value": {
"stat_prefix": "http_local_rate_limiter",
"enable_x_ratelimit_headers": "DRAFT_VERSION_03",
"token_bucket": {
"max_tokens": 50,
"tokens_per_fill": 10,
"fill_interval": "120s"
},
"filter_enabled": {
"default_value": {
"numerator": 100
},
"runtime_key": "local_rate_limit_enabled"
},
"filter_enforced": {
"default_value": {
"numerator": 100
},
"runtime_key": "local_rate_limit_enforced"
}
}
}
},
{
"name": "istio.metadata_exchange",
"typed_config": {
...
]
Note
You can useistioctl dash envoy deploy/httpbinto see the Envoy configuration for a specific workload.
Let's test the rate limiter by sending a bunch of requests to the
httpbin service and try to trigger the rate limiter. I've created another Pod inside the cluster that I am using to send the request.From within that Pod, I use this script to send bunch of requests to the
httpbin service:while true; do curl http://httpbin.default.svc.cluster.local:8000/headers; done
Once 50 requests are sent, you'll notice the
local_rate_limited responses and the HTTP 429. You can press CTRL+C to stop sending requests.$ curl -v httpbin:8000/headers
> GET /headers HTTP/1.1
> User-Agent: curl/7.35.0
> Host: httpbin:8000
> Accept: */*
>
< HTTP/1.1 429 Too Many Requests
< content-length: 18
< content-type: text/plain
< x-ratelimit-limit: 50
< x-ratelimit-remaining: 0
< x-ratelimit-reset: 96
< date: Sun, 04 Sep 2022 22:46:50 GMT
< server: envoy
< x-envoy-upstream-service-time: 1
<
local_rate_limited
The
x-ratelimit-* headers are added by the rate limiter filter, and they show the original limit, remaining tokens, and the time until the next refill (reset)If you wait for 2 minutes (the
fill_interval we've configured) you'll notice that the rate limiter will allow you to send more requests.We could also configure a response header and a different HTTP code and remove the
x-ratelimit-* headers.Note
The HTTP status codes are represented as an enum in Envoy, so we can't just put a number there. We need to use the enum name.
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: httpbin-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
app: httpbin
version: v1
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_INBOUND
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append_action: APPEND_IF_EXISTS_OR_ADD
header:
key: x-rate-limited
value: TOO_MANY_REQUESTS
status:
code: BadRequest
If we apply the above resource and re-run the test, we'll see the following response:
$ curl -v httpbin:8000/headers
> GET /headers HTTP/1.1
> User-Agent: curl/7.35.0
> Host: httpbin:8000
> Accept: */*
>
< HTTP/1.1 400 Bad Request
< x-rate-limited: TOO_MANY_REQUESTS
< content-length: 18
< content-type: text/plain
< date: Sun, 04 Sep 2022 23:03:26 GMT
< server: envoy
< x-envoy-upstream-service-time: 5
<
local_rate_limited
Rate limiter metrics
The rate limit filter in Envoy automatically generates the following metrics:
| Metric | Description |
|---|---|
<stat_prefix>.http_local_rate_limit.enabled | Total number of requests for which the rate limiter was consulted |
<stat_prefix>.http_local_rate_limit.ok | Total number of under limiter responses from the token bucket |
<stat_prefix>.http_local_rate_limit.rate_limited | Total number of responses without a token (but not necessarily enforced) |
<stat_prefix>.http_local_rate_limit.enforced | Total number of rate limited responses (e.g., when 429 is returned) |
Note the metrics are prefixed with the
<stat_prefix>.http_local_rate_limit, where <stat_prefix> is the value we've configured in the stat_prefix field (e.g. http_local_rate_limiter).Note
You might wonder why we use a generichttp_local_rate_limitername for thestat_prefixfield. The reason is that it allows us to use the same metric name and then use attributes such asapporversionto differentiate between rate limiters on different workloads.
To see these metrics in Prometheus we need to explicitly enable them. We can do that by annotating the
httpbin deployment (the Pod spec template) to tell Istio to enable collection of the http_local_rate_limit statistics from Envoy:template:
metadata:
annotations:
proxy.istio.io/config: |-
proxyStatsMatcher:
inclusionRegexps:
- ".*http_local_rate_limit.*"
Because we must annotate the Pod spec template, we need to use
kubectl patch to do it:kubectl patch deployment httpbin --type merge -p '{"spec":{"template":{"metadata":{"annotations":{"proxy.istio.io/config":"proxyStatsMatcher:\n inclusionRegexps:\n - \".*http_local_rate_limit.*\""}}}}}'
Once the deployment is patched, the Pods will restart automatically. If we send a few requests to the
httpbin service, we'll see the following metrics from the Envoy sidecar:# TYPE envoy_http_local_rate_limiter_http_local_rate_limit_enabled counter
envoy_http_local_rate_limiter_http_local_rate_limit_enabled{} 179
# TYPE envoy_http_local_rate_limiter_http_local_rate_limit_enforced counter
envoy_http_local_rate_limiter_http_local_rate_limit_enforced{} 129
# TYPE envoy_http_local_rate_limiter_http_local_rate_limit_ok counter
envoy_http_local_rate_limiter_http_local_rate_limit_ok{} 50
# TYPE envoy_http_local_rate_limiter_http_local_rate_limit_rate_limited counter
envoy_http_local_rate_limiter_http_local_rate_limit_rate_limited{} 129
Now that we know how to configure the rate limiter filter for workloads inside the mesh let's see how we can configure the rate limiter at the ingress gateway.
Rate limiting at the ingress gateway
We can configure the rate limiter at the ingress gateway as well. We can use the same configuration as before, but we need to apply it to the
istio-ingressgateway workload instead. Because there's a differentiation between the configuration for sidecars and gateways, we need to use a different context in the EnvoyFilter resource (GATEWAY).Everything else stays the same:
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: ingress-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
istio: ingressgateway
configPatches:
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
subFilter:
name: 'envoy.filters.http.router'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append_action: APPEND_IF_EXISTS_OR_ADD
header:
key: x-rate-limited
value: TOO_MANY_REQUESTS
status:
code: BadRequest
To test this configuration, we need to expose the
httpbin workload through the ingress gateway. We can do that by creating a Gateway and a VirtualService resource:apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- '*'
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- '*'
gateways:
- gateway
http:
- route:
- destination:
host: httpbin.default.svc.cluster.local
port:
number: 8000
Let's apply this configuration first and try it out:
export GATEWAY_IP=$(kubectl get svc -n istio-system istio-ingressgateway -ojsonpath='{.status.loadBalancer.ingress[0].ip}')
curl $GATEWAY_IP/headers
{
"headers": {
"Accept": "*/*",
"Host": "34.168.44.88",
"User-Agent": "curl/7.74.0",
"X-B3-Parentspanid": "9d24ff54dd5b10f1",
"X-B3-Sampled": "1",
"X-B3-Spanid": "f9aa7bf2e4284b6f",
"X-B3-Traceid": "13bb49a9d3af3cb79d24ff54dd5b10f1",
"X-Envoy-Attempt-Count": "1",
"X-Envoy-Internal": "true",
"X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/default/sa/httpbin;Hash=d17dc0e96cfdd66c73a0b5664e69a82a8b07dfae92f7386439bff75ed3730ea0;Subject=\"\";URI=spiffe://cluster.local/ns/istio-system/sa/istio-ingressgateway-service-account"
}
}
As you can see, the request was successful. Now let's apply the rate limiter configuration and try again:
while true; do curl $GATEWAY_IP/headers; done
Once the rate limiter kicks in, we'll see the same responses as before:
$ curl -v $GATEWAY_IP/headers
* Trying 34.168.44.88:80...
* Connected to 34.168.44.88 (34.168.44.88) port 80 (#0)
> GET /headers HTTP/1.1
> Host: 34.168.44.88
> User-Agent: curl/7.74.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 400 Bad Request
< x-rate-limited: TOO_MANY_REQUESTS
< content-length: 18
< content-type: text/plain
< date: Sun, 04 Sep 2022 23:22:18 GMT
< server: istio-envoy
< connection: close
<
* Closing connection 0
local_rate_limited
If we open Prometheus we can now visualize the rate limiters for both the httpbin workload and the ingress gateway. We can use the same metric name, but specify the app name as an attribute.
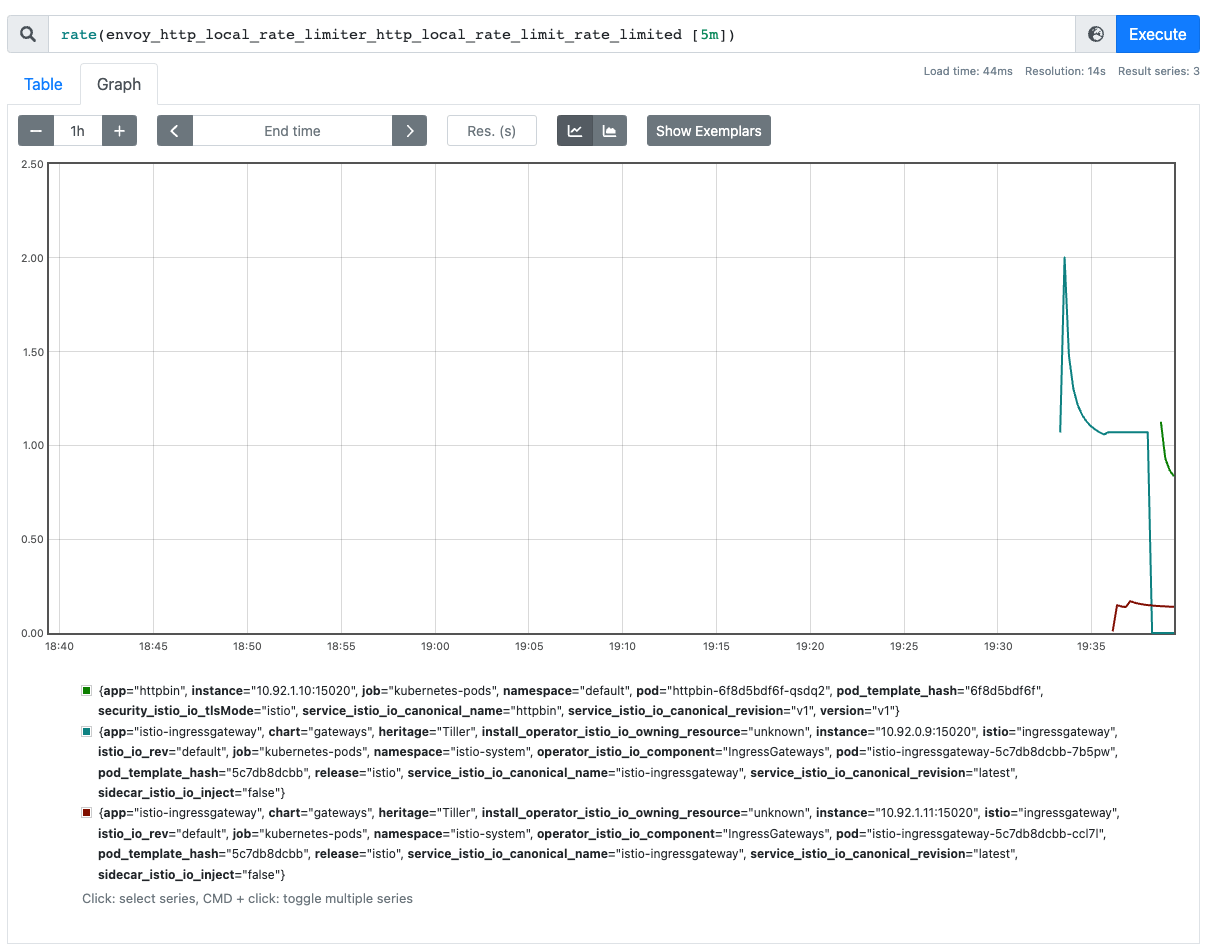
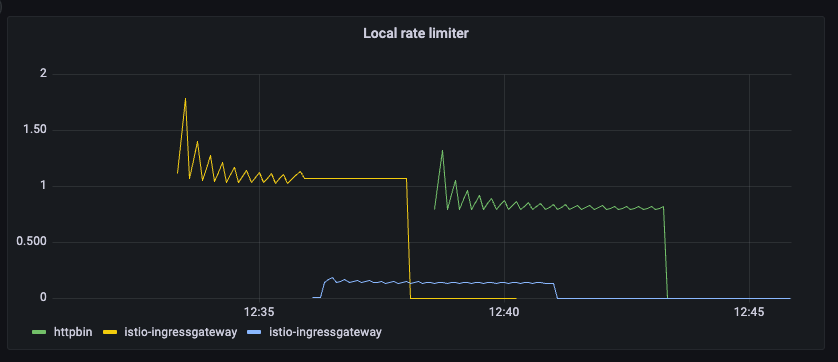
We can take this a step further and also create a dashboard for the rate limiter metrics in Grafana.
Rate limiting at the egress gateway
The rate limiter at ingress can protect the mesh from external traffic. However, we can also configure the rate limiter at the egress gateway to protect the external services from the calls inside the mesh. This is useful when we want to limit the number of requests to a specific external service.
To demonstrate the rate limiter at egress, I'll use the egress gateway example from Istio documentation. You can follow the instructions in the documentation to deploy the example.
The example involves doing the following:
- Deploying a
sleepworkload - you don't necessarily need to do this; we'll use thecurlPod from the previous example - Enabling Envoy access logs. Technically, you don't need to do this to confirm the rate limiter is working, as we'll get a 429 response, but it's helpful to see the logs to make sure traffic is going through the egress gateway)
- Deploying an egress gateway (if you don't have one already)
- Creating the ServiceEntry, Gateway, DestinationRule, and VirtualService resources to route the traffic to the external service (
edition.cnn.com)
To check you've deployed everything correctly, look at the logs from the egress gateway, and you should see a log entry in there:
...
[2022-09-04T23:28:56.017Z] "GET /politics HTTP/2" 301 - via_upstream - "-" 0 0 21 20 "10.92.1.6" "curl/7.85.0-DEV" "ecad53e2-e6de-929b-8592-94468a55cef7" "edition.cnn.com" "151.101.195.5:80" outbound|80||edition.cnn.com 10.92.2.9:32836 10.92.2.9:8080 10.92.1.6:35122 - -
...
The log entry shows that the requests made inside the mesh go through the egress gateway. Now let's configure the rate limiter at the egress gateway.
Since the egress gateway is configured for a specific host (
edition.cnn.com), we'll do the same in the rate limiter and configure it to only apply to the edition.cnn.com:80 virtual host. Let's look at the EnvoyFilter:apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: egress-ratelimit
namespace: istio-system
spec:
workloadSelector:
labels:
istio: egressgateway
configPatches:
- applyTo: HTTP_FILTER
match:
context: GATEWAY
listener:
filterChain:
filter:
name: 'envoy.filters.network.http_connection_manager'
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.local_ratelimit
typed_config:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
- applyTo: HTTP_ROUTE
match:
context: GATEWAY
routeConfiguration:
vhost:
name: 'edition.cnn.com:80'
route:
action: ANY
patch:
operation: MERGE
value:
typed_per_filter_config:
envoy.filters.http.local_ratelimit:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
value:
stat_prefix: http_local_rate_limiter
token_bucket:
max_tokens: 50
tokens_per_fill: 10
fill_interval: 120s
filter_enabled:
runtime_key: local_rate_limit_enabled
default_value:
numerator: 100
denominator: HUNDRED
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
response_headers_to_add:
- append_action: APPEND_IF_EXISTS_OR_ADD
header:
key: x-rate-limited
value: TOO_MANY_REQUESTS
status:
code: BadRequest
This time resource looks more complex because we're enabling the rate limiter for a specific virtual host. To do that, we still need to insert the rate limiter filter like before. However, we must also add the
typed_per_filter_config to the route configuration. This is where we configure the rate limiter for the specific virtual host. Because we need to target a particular virtual host, we'll provide the routeConfigurationin the match section. Inside that, we're targeting a specific virtual host (edition.cnn.com:80) and all routes on that host (action: ANY). Note that we're using the' MERGE' operation because the virtual host and route configuration already exist.Let's create the EnvoyFilter, go to the
curl Pod, and try to send requests to edition.cnn.com:$ curl -v edition.cnn.com
> GET / HTTP/1.1
> User-Agent: curl/7.35.0
> Host: edition.cnn.com
> Accept: */*
>
< HTTP/1.1 400 Bad Request
< x-rate-limited: TOO_MANY_REQUESTS
< content-length: 18
< content-type: text/plain
< date: Sun, 04 Sep 2022 23:42:52 GMT
< server: envoy
< x-envoy-upstream-service-time: 1
<
local_rate_limited
Note that if we sent a request to a different external service, we wouldn't get rate limited as we applied the configuration to only one virtual host.
Conclusion
In this post, we've seen how to use and configure the local Envoy rate limiter filter to limit the number of requests sent to services. We explained how Envoy's local rate limiter works and how to configure it. We used a simple example to configure the local rate limiter to a workload running inside the mesh.
We've also demonstrated a scenario where we configure the local rate limiter to ingress and egress gateways. The only difference in configuring the rate limiter for ingress and egress gateways is that we need to change the workload selectors (of course) and change the context we're applying the EnvoyFilter resource to. In the case of the egress gateways, we've shown a more complex scenario. We've configured the traffic to a specific external service to go through the egress gateway and then configured the rate limiter to only apply to that particular external service. We've used the route configuration and targeted a specific virtual host instead of applying the rate limiter to all virtual hosts.
In this post, we've applied the local rate limiters across the service - we didn't differentiate, for example, between the GET or POST requests, different paths, and so on. In the next post, I'll explain how to configure a global rate limiter and apply it to specific routes, paths, and methods. For example, we'll learn how to use a rate limiter with different settings to
GET requests on /api/v1/posts path, or POST requests on /api/v1/users path, and so on.Related reading:
- Global Rate Limiting in Istio with Envoy Rate Limit Service
- Circuit Breaking in Istio Explained
- Free Istio training path — 15+ hands-on tutorials
I hope you enjoyed this post and learned something new. If you have any questions, please contact me on Twitter or send me a message.





