
CAP theorem or Brewers theorem (named after computer scientist Eric Brewer) often gets mentioned in combination with distributed systems.
The theorem states that it is impossible for a distributed system to have more than two of the following three properties:
- Consistency
- High Availability
- Partition tolerance
Note
Distributed system is a collection of computers that are connected through a network and appear as a single computer.
What is consistency?
We have a cluster of four computers that are connected to each other and two operations that we can the cluster understands:
read and write. The read operation returns a value that is stored, and write updates the stored value in the cluster.In the current state of the cluster, all computers have a value called
Hello stored as shown in the figure below.
Let's say we want to update the value from
Hello to Bye and call the write operation. We make the call to the cluster and the call ends up on computer 1 (top left) and the value gets updated as shown below.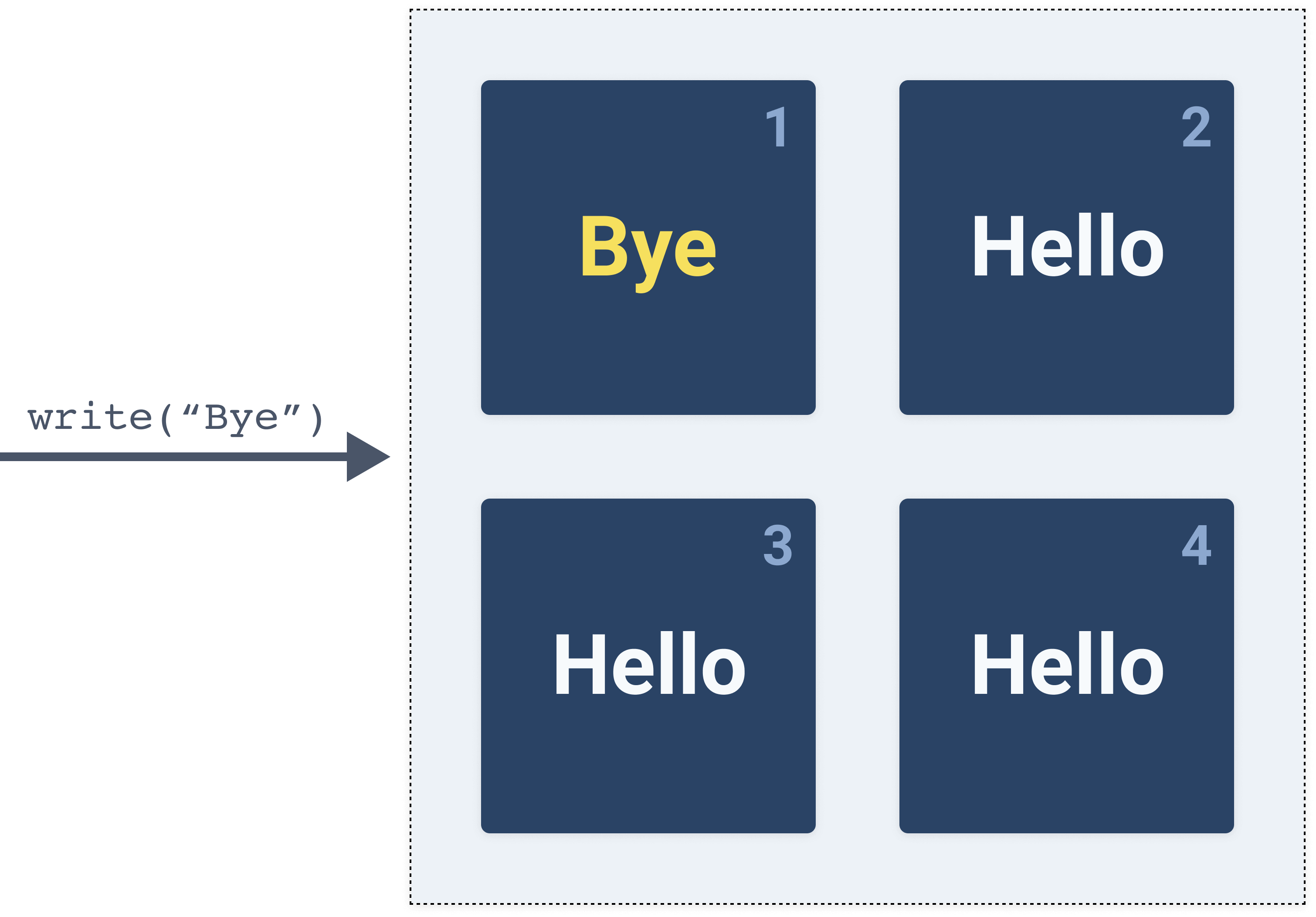
As soon as that write operation happens, the value should get replicated to other computers in the cluster. However, if we try to read the value before the replication happens and the call ends up on computer 3 for example (bottom left), we will get back value
Hello. If that happens, we can say that the system is inconsistent.Consistency is saying that every computer or node in the system provides the most recent state and that no node in the system will return an outdated state.
What is availability?
Using the same cluster, let's assume two of the nodes went offline and are not reachable by other nodes.

To say the system is available it would mean that we can invoke
read and write operations and get back a response, even though there are unavailable nodes in the cluster.What is partition tolerance?
Partition is the inability of two or more nodes in the network to communicate with each other.
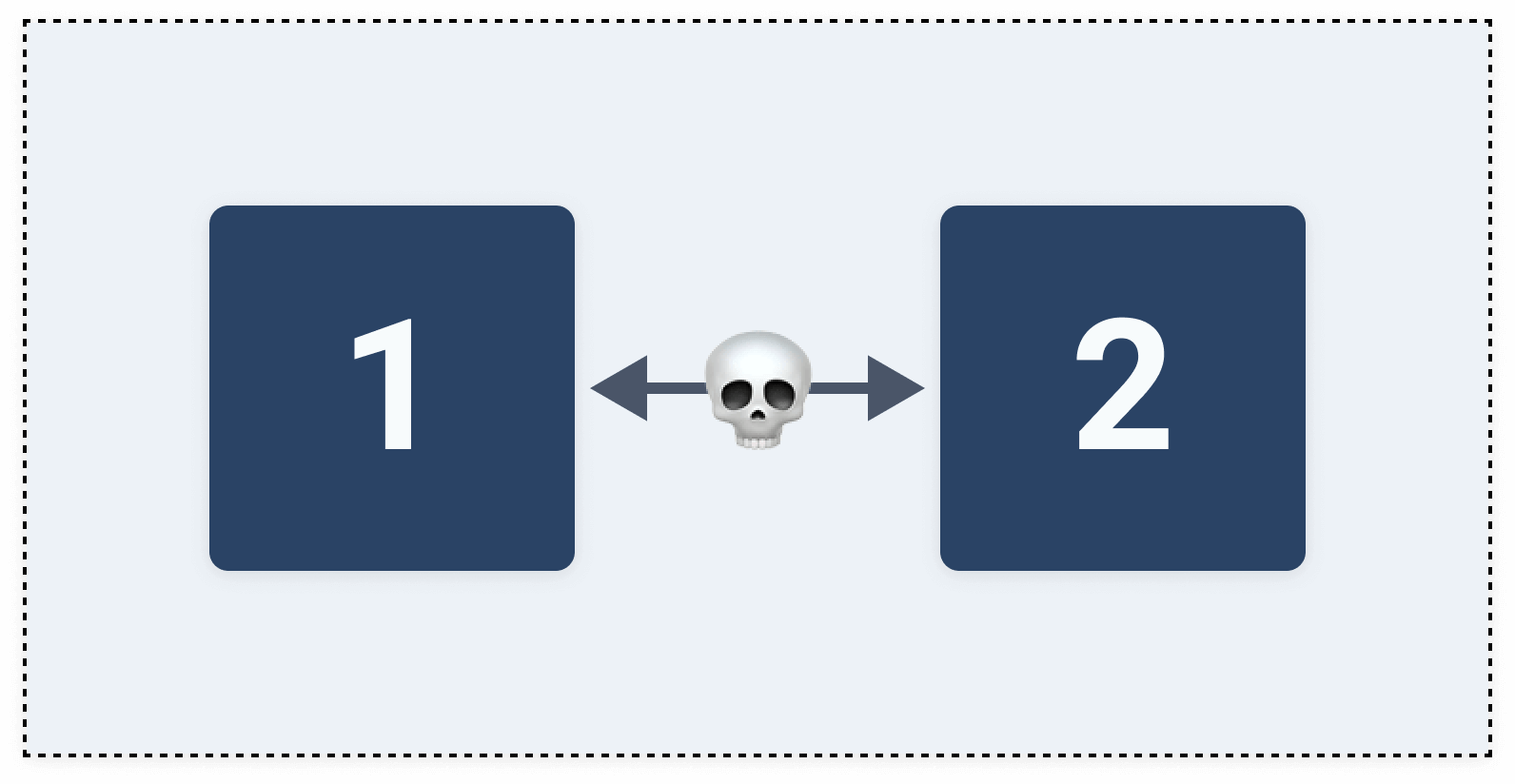
If node 1 cannot receive messages from node 2, it means that there is a partition between them, and the message send from one node will not reach the other node.
Partition tolerance is saying that even though the connection between nodes is severed (or that there are partitions), the system should still be up and running.
What follows is a couple of different scenarios that prove systems can only have two out of the three properties.
Partition tolerant and available system
If we want the system to be partition tolerant and available, we will be sacrificing consistency.
We call the
write("Bye") operation and the call end up on node 1.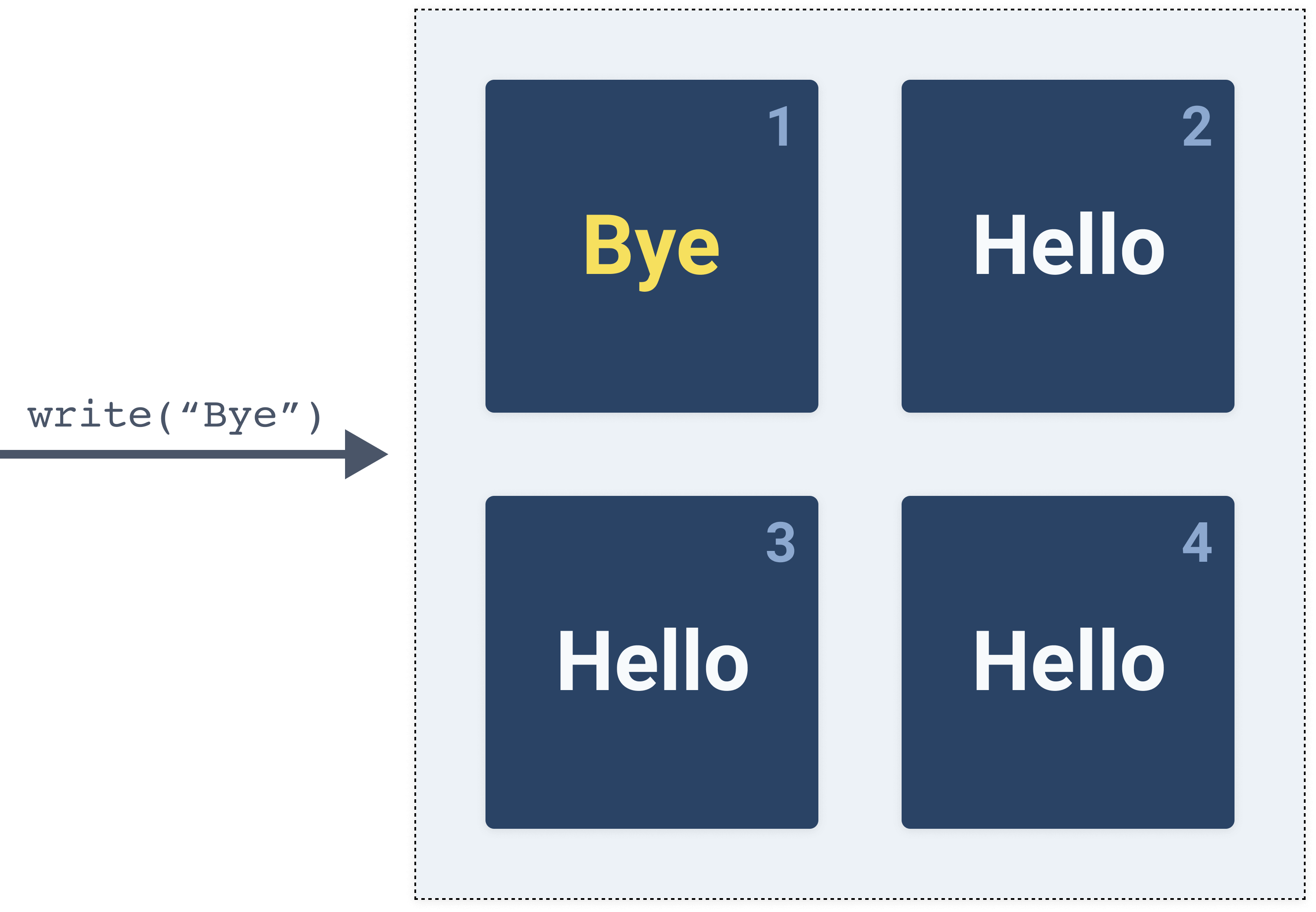
Node 1 tells other available nodes to update their state, however nodes 2 and 4 cannot receive updates (there's a partition). The nodes are not aware of the updated state and keep the old value (
Hello).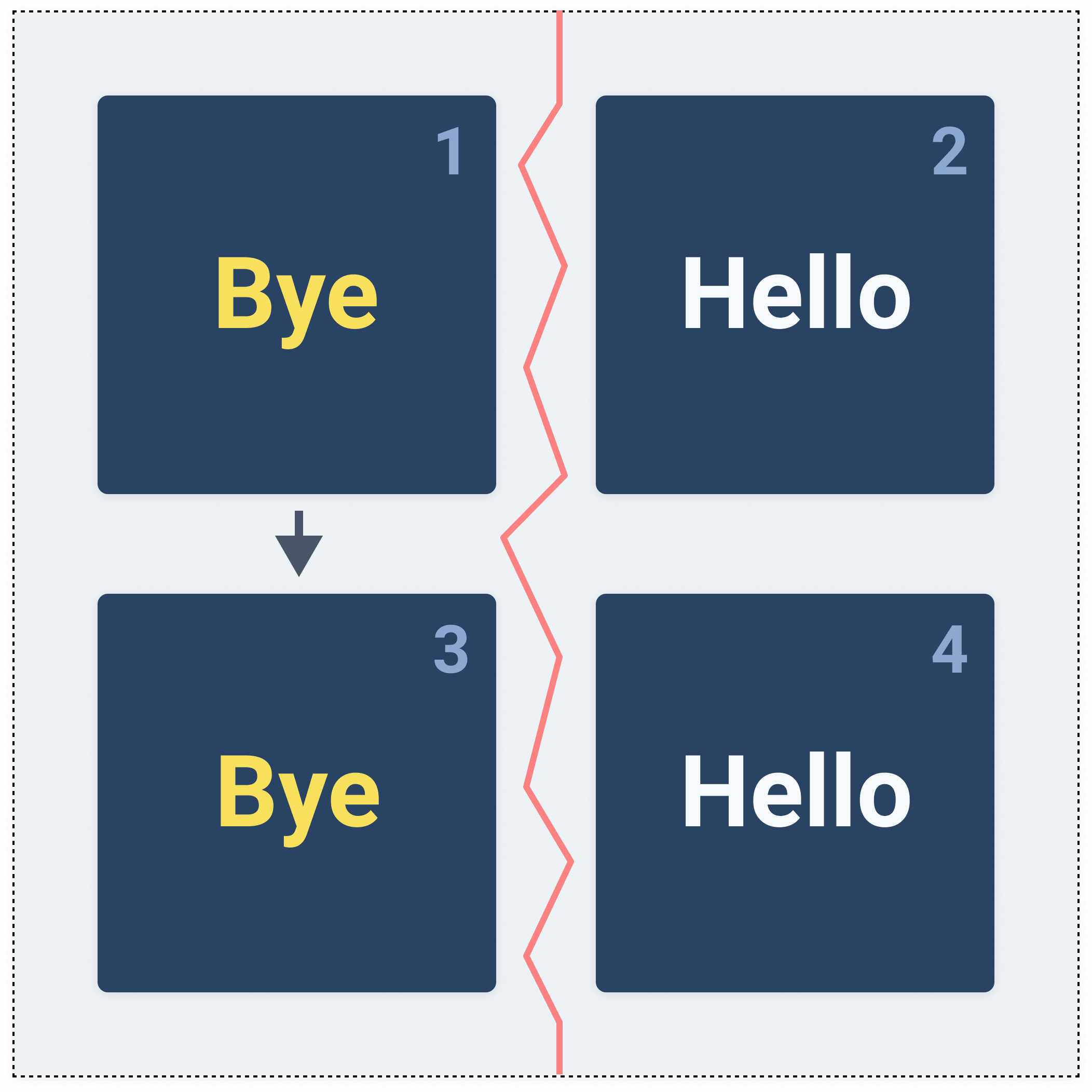
Later, if we call the
read operation and the call ends up on either node 2 or 4, we get back the value of Hello. However, since this is not the recent state (as per consistency definition) which makes the system inconsistent, but partition tolerant and available.Partition tolerant and consistent system
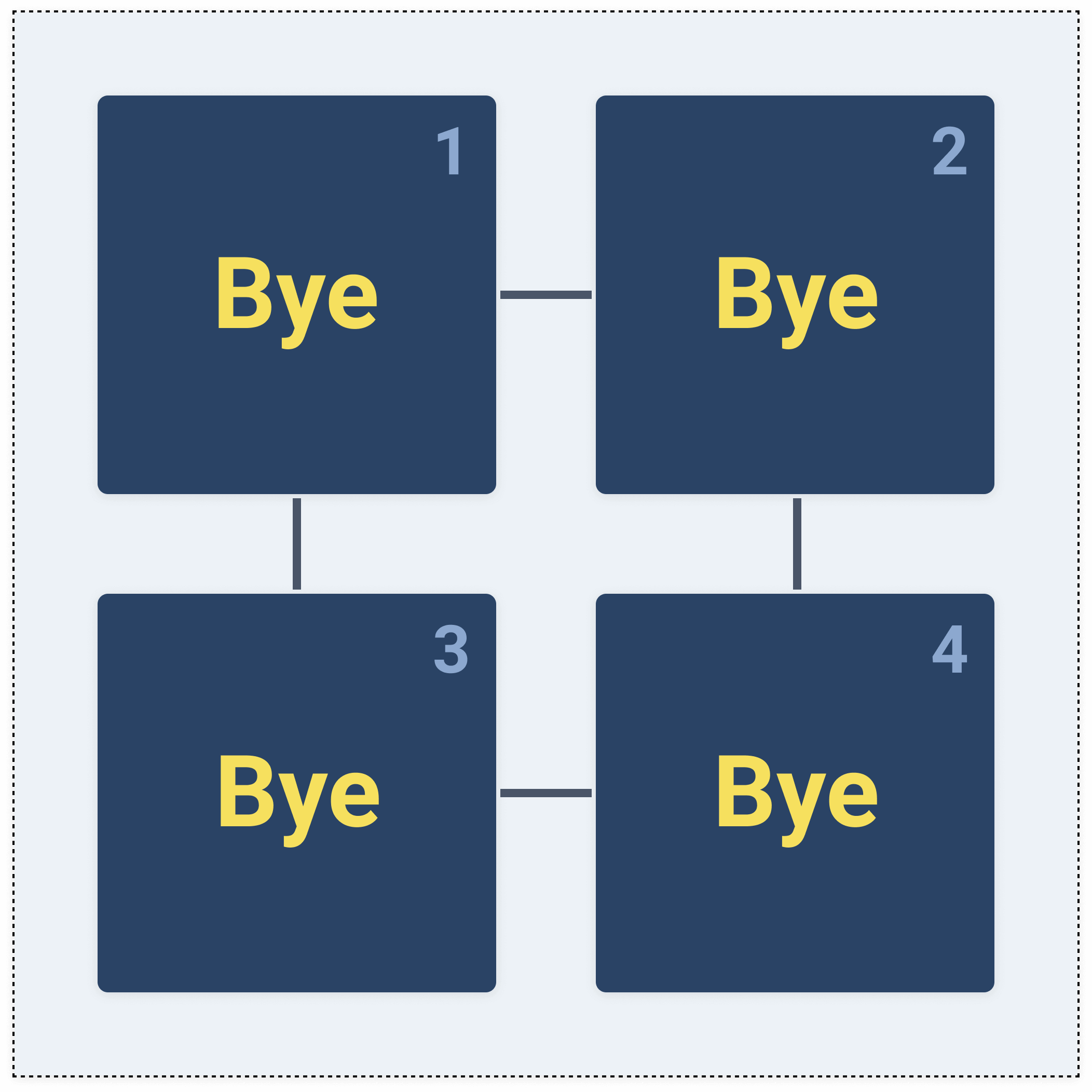
The second combination we are looking at is a partition tolerant and consistent system. In this case, we are losing the availability property.
We have the exact same scenario as before. We update node 1 and the value gets replicated to node 3, but not on nodes 2 and 4 as there's a partition.
What is going to happen when
read operation is invoked and the call ends up on node 2 for example?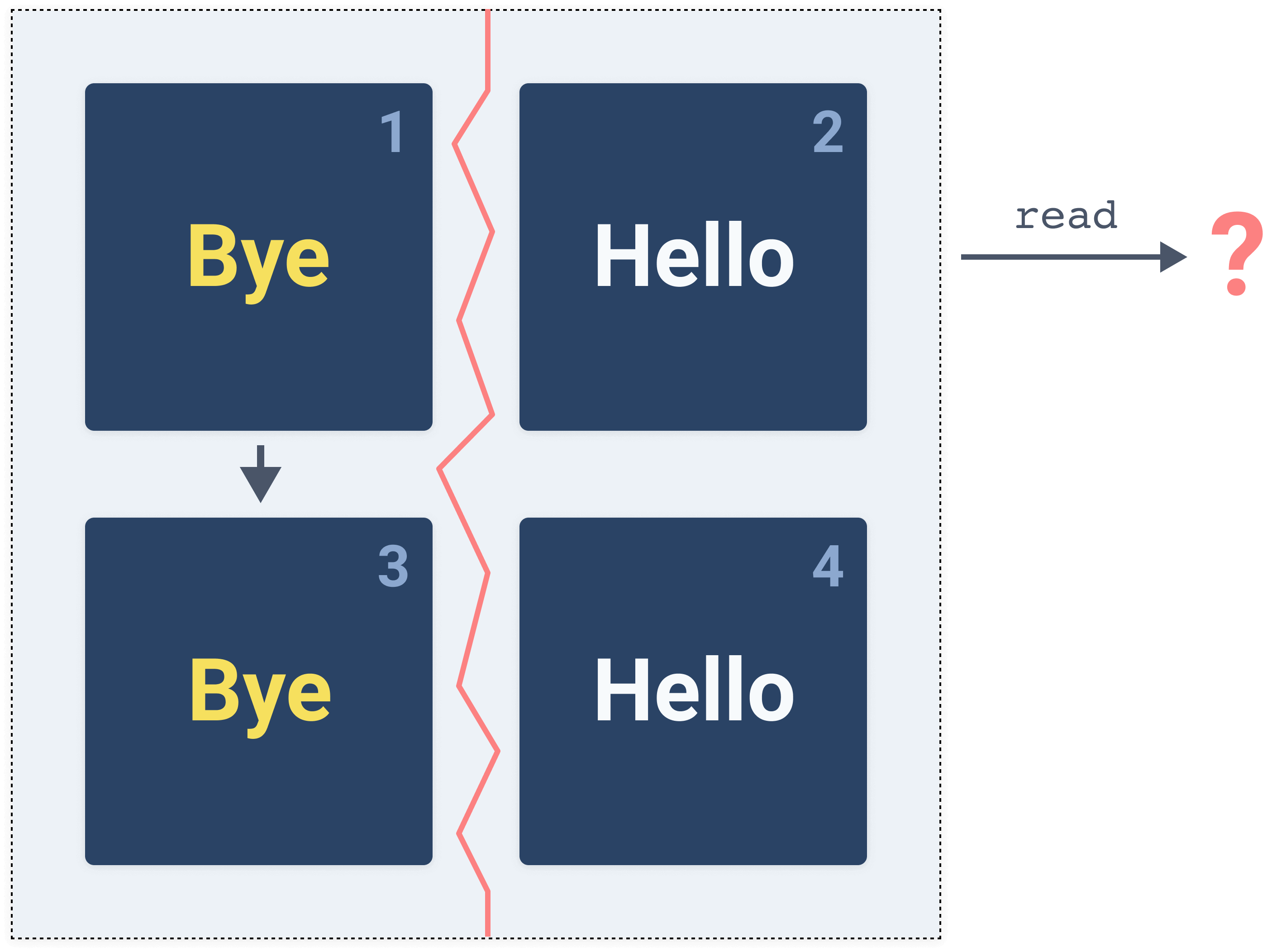
Node 2 cannot return any values, because it's bound to consistency which says that every node provides the most recent state and will never return an outdated state. The way a certain node knows it has an outdated value is to ask other nodes for an updated state. If it doesn't hear back from all nodes, it assumes it's outdated and it won't return a value.
Consistent and available system
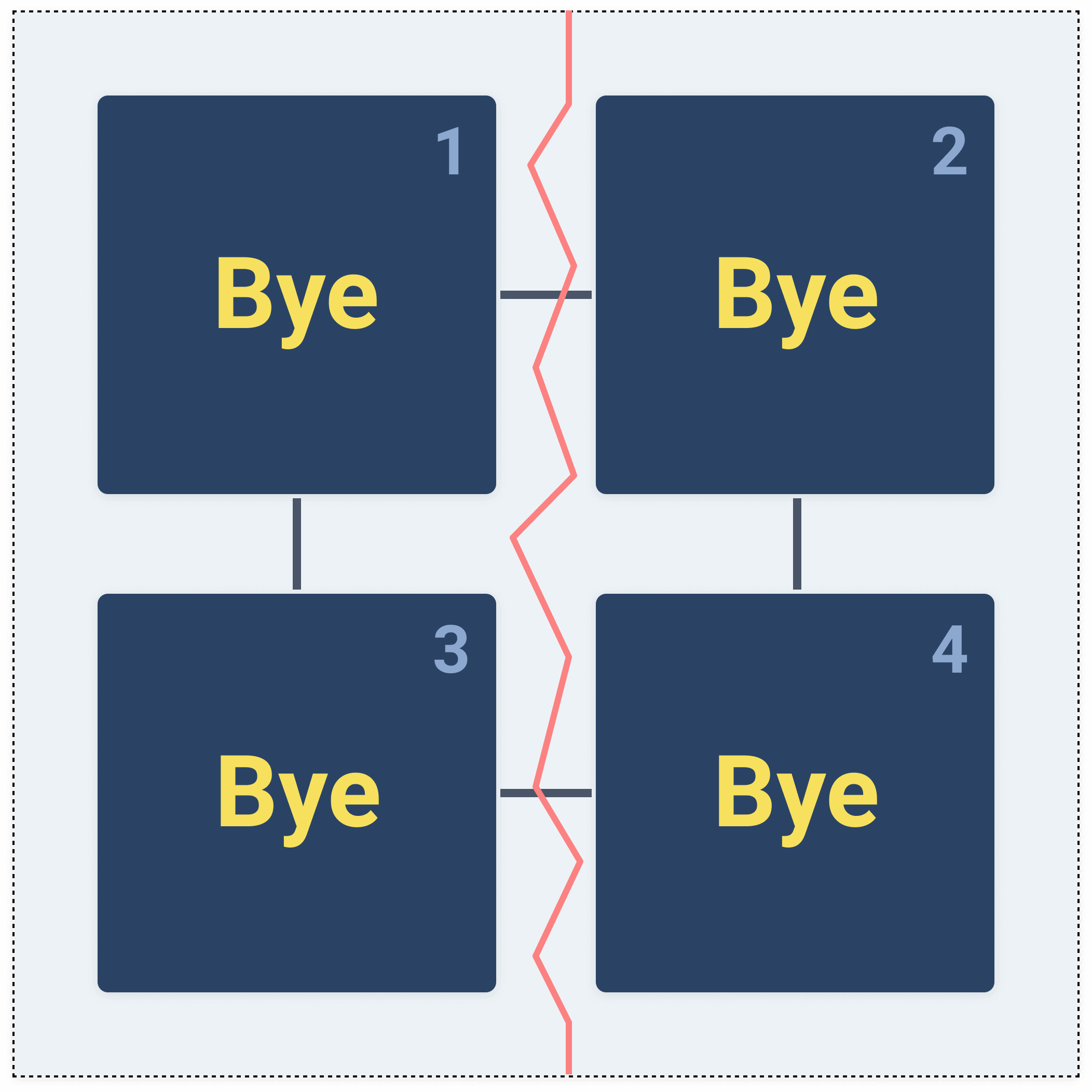
In the final scenario we want our system to be consistent and available.
Same flow as before: we update node 1, the values get replicated to all nodes in the cluster. Later, we try to read from node 2 and we get the latest value.
Everything looks good!
However, as soon as there's a network partition, nothing works anymore and we are forced into one of the previous two situations.
Conclusion
What this shows is that systems need to compromise. We know networks are not reliable and that there will always be network issues or partitions, even if it's not a completely severed connection, it could simply be network latency.
For that reason, partition tolerance is one of the properties that's already picked for us. This gives us the option of choosing between consistency or availability.
When you pick consistency over availability, your system will return an error or time out if the consistency cannot be guaranteed.
When you pick availability over consistency, the system will always process the request and try to return the most recent available value, even if it cannot guarantee that it is the latest value.
If there are no network partitions, both availability and consistency can be satisfied.
The examples given above are extremes - you don't really have to completely abandon one or another property. You need to figure out what are you going to do and how your system will behave if there are network partitions - you can always retry the call or try to be eventually consistent and return the not-the-most-recent value.





